오늘의 연구

최근 AI 연구 4개와 내가 생각하는 AI의 미래에 대해 정리했다.
- π0.5: a Vision-Language-Action Model with Open-World Generalization
- GelSLAM: A Real-time, High-Fidelity, and Robust 3D Tactile SLAM System
- Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
- Robix: A Unified Model for Robot Interaction, Reasoning and Planning
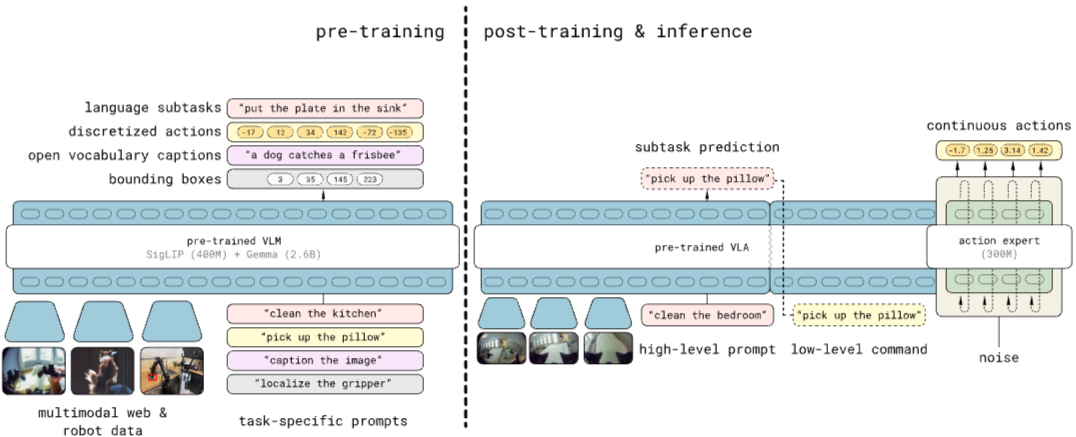
1. π0.5


5배속해서 보여주는 게 느려서 정배속으로 보기 힘든 Kiro를 보는 것 같다. 살짝 위안이 된다.
- 데이터
- Diverse Mobile Manipulator data (MM), Diverse Multi-Environment non-mobile robot data (ME), Cross-Embodiment laboratory data (CE), High-Level subtask prediction (HL), Multi-modal Web Data (WD)
- 5개의 다양한 데이터셋을 사용한 "co-training"
- Generalization을 위해 다양한 형태의 knowledge transfer가 필수적임을 보임
- 데이터셋에 따라 로봇이 달라 액션 차원도 다른데 normalize하고 padding해서 학습함
- 사고
- System 1, 2로 분리되어 있음.
- pre-training VLA를 통해 태스크를 수행하기 위한 sub-task를 텍스트로 생성.
- 이후 System 2인 Action Expert로 sub-task -> continuous action 생성
- 액션 생성
- pre-training에서 FAST 토크나이저를 통해 액션도 토큰으로 표현. next-token prediction으로 학습.
- post-training에서 Action Expert가 action token을 continuous actions으로 디코딩하도록 학습. flow-matching으로 discrete action token을 continuous action으로 변환. continuous action 변환할 때 action token 이외에 다른 어떤 정보도 쓰지 않음.
- inference에서는 고수준에선 discrete token, 저수준에선 flow-matching으로 continuous action 생성
- Verbal Instruction (high-level task를 수행하기 위한 구체적인 자연어 설명) 사용
"다양한 태스크 데이터셋을 함께 사용하여 knowledge transfer 가능"한 점이 이 논문에서 배울 부분. System 1, 2 나누는 것이나 next-token prediction이나 flow matching 쓰는 것은 다른 연구들과 다 같은 결. 하지만 이 정도 완성도의 로봇을 만들었다는 건 뒤에 안 보이는 엄청난 엔지니어링이 있을 것. pi 응원하게 되는 팀이다. 꾸준히 성과가 나온다.
2. GelSLAM

햅틱 센서만 사용하여 물체의 pose를 추정하고 고정밀 3D 모델을 재구성하는 실시간 3D 슬램 시스템
우리가 물리적 공간에 존재하면서 시각이 중요하다고 느끼지만 사실 촉각이 정말정말 중요하다. 키보드 타이핑칠 때 손에 느껴지는 감각 빼고 타이핑치면 오타 엄청날거고, 촉각 없이 종이도 넘기기 어렵다. 하지만 눈 감고 타이핑칠 수 있으며, 책을 넘길 수 있다. 시각과 촉각이 함께면 더욱 정확하게 모델링이 가능해진다. 또한 시각으로 커버가 안되는 사각지대에서의 물체들도 촉각으로 대략적인 것들을 예측 가능하다.
촉각 자체를 더욱 정밀하게 느낄 수 있는 센서도 더욱 발전해야 하고, 이 센서를 지능에 통합하는 것도 더욱 발전해야 한다. tactile base 3D reconstruction task 논문 재밌게 읽었다.
3. Discrete Diffusion VLA
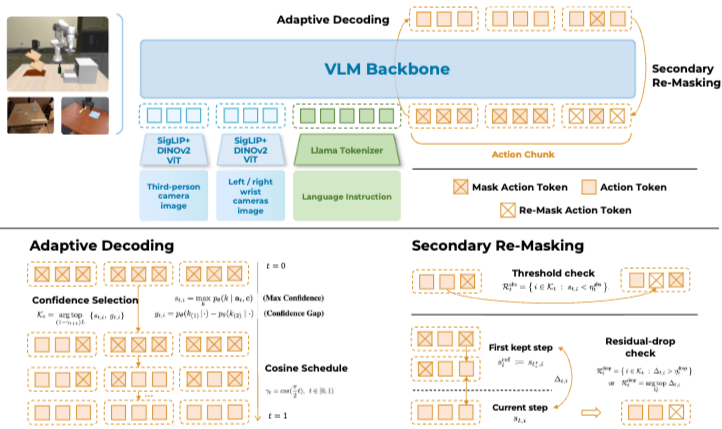
이전에는 auto-regressive하게 다음 액션을 추론하는 AR 방식과 전체 행동 궤적을 반복적으로 denoise하는 continuous diffusion 방식 2가지가 있었다.
continuous diffusion은 AR보다 세련되게 움직일 수 있었지만 VLM backbone을 제대로 활용할 수 없었다. 이 장점들을 모두 살리고 단점은 가리기 위해 VLM backbone을 활용하여 discrete해지지만 diffusion으로 부드럽게 움직일 수 있도록 하는 discrete diffusion VLA를 제안한다.
학습할 땐 BERT처럼 랜덤하게 토큰을 마스킹하여 추론한다. 추론 시에는 쉬운 것부터 하나씩 denoise하면서 한번 추론 잘못하면 수정이 불가능한 AR 방식과 다르게 추론하면서 행동 교정도 가능하다.
장점도 많지만 continuous diffusion이 아니기에 binning 형태로 액션하다 보니 정밀한 포즈 제어는 어렵다.
나중에 로봇이 AR로 귀결이 될지 Diffusion으로 귀결될지 궁금하다.
4. Robix
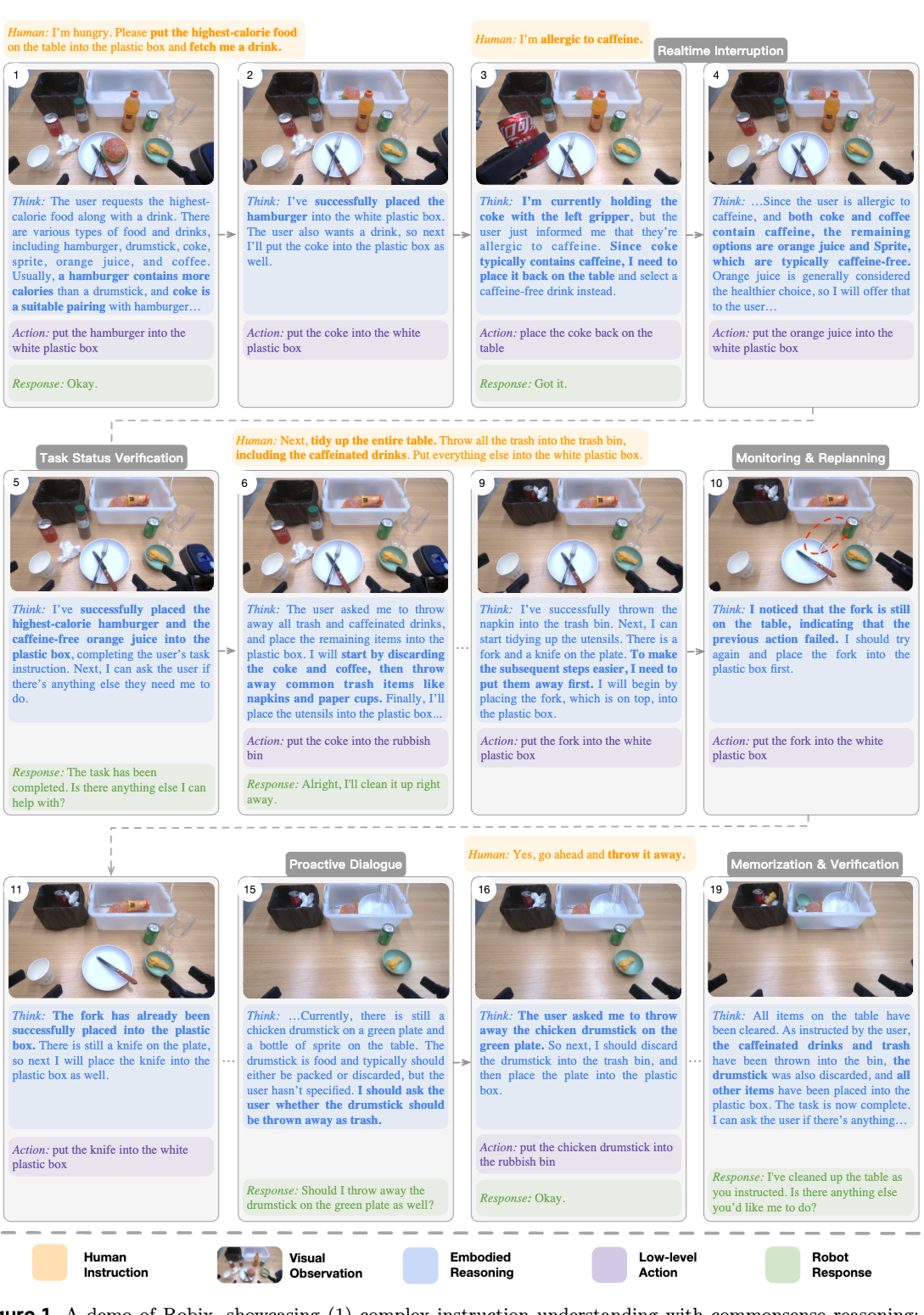
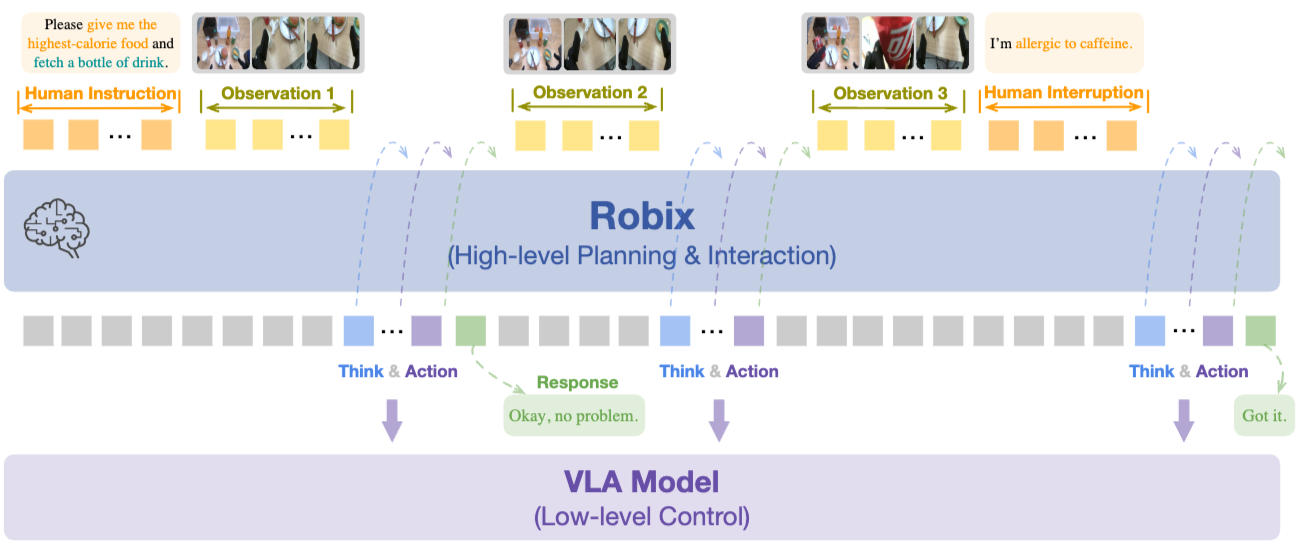
대체로 다른 연구와 비슷한데 realtime interruption handling이 되고 robot text response가 존재한다.
- continual pretraining, supervised finetuning, reinforcement learning 3단계로 학습했으며 continual pretraining에서는 pi0.5처럼 다양한 태스크 데이터셋으로 co-training했다.
- Robix 시스템을 잘 만들었고 SFT 단계에서 data synthesis를 잘했다. Teleoperation하고 라벨링해서 labeled teleoperation data 모으고, 시뮬레이션이나 text-to-image로 합성. SOTA VLM으로 trace (사고 흐름) 가상으로 생성. 이것으로 Reasoning 학습.

AI의 미래
Physical AI라는 말이 조만간 사라지지 않을까 생각해본다. AI라고 부르면 기본적으로 Physical AI가 되고 오히려 지금의 LLM 처럼 non-physical로 존재하는 AI들을 Non-physical AI라고 부르지 않을까? Physical AI가 AI의 기본적인 형태가 될 것이라고 본다. 물리적 환경을 이해하고 있는 AI가 현재의 AI보다 더 깊은 이해를 가지게 될 것이기에 물리적 출력이 없는 태스크에서도 결국은 Physical AI가 더 잘하게 될 것이니까.
데이터
Physical AI의 데이터를 모으는 것이 빅테크와 스타트업의 차이가 크게 없을 것이라 생각한다. 근본적으로 텍스트나 이미지는 웹이라는 환경이 있었지만 Physical에서는 그런 환경이 아예 없어 모두 동일하게 맨땅에서 만들어가야 한다. LLM의 성공을 보면 large-scale & low quality data에서 SFT(Off-policy)로 학습을 먼저 하고 그 뒤로 small-scale & high quality data로 RLHF(On-policy)로 학습했다. 이 큰 패러다임은 Physical에서도 비슷할 것 같다.
Physcical에서 synthetic하게 학습하고 있긴 하지만 이건 분명 한계가 있다. VLM 대비 훨씬 지능이 낮아서 이게 학습이 되는 것이지 VLM의 2-30% 수준만 되어도 synthetic data로 제대로 배우기가 어려울 것이라 생각한다. 내가 생각하는 데이터는 크게 4가지 형태이다.
- 오프라인에서 사람이 모으는 데이터 (시각, 청각, 촉각) - 데이터 수집기 세트 (카메라 내장 안경, 녹음기, 촉각 수집 장갑) 장착하기
- 온라인에서 사람이 모으는 데이터 - 고도화된 시뮬레이션 환경에서 시각, 청각, 촉각을 기반으로 행동 수행
- 오프라인에서 AI가 모으는 데이터 - 물리적으로 실환경에서 존재하는 로봇이 on-policy로 수행하면서 배우기
- 온라인에서 AI가 모으는 데이터 - 가상환경에서 존재하는 로봇이 시뮬레이션 환경에서 태스크 수행
1, 2는 SFT에, 3, 4는 RL에 쓰이게 될 것이다. 1, 2는 off-policy. 3, 4는 on-policy. (1, 2 모두 텔레오퍼레이션 포함이다.)
1로 질 좋은 데이터를 모으고, 2로 데이터의 variation을 펌핑시키고, 1, 2로 어느 정도의 개념을 파악한 AI가 4로 가상공간에서 체화시키고, 마지막으로 3으로 sim2real gap까지 완벽하게 이해하고 학습하는 형태가 될 것이라고 생각한다.
입력
흔히 우리가 말하는 multi-modal 측면에서 보면 현재 텍스트, 이미지 정도가 제대로 된 multi-modality를 갖췄고 청각, 촉각까지는 아직 많이 남았다. 시각, 청각, 촉각이 다 함께 센싱되어 사고할 수 있는 AI! 언어는 확실히 별도로 분리되어야 하는 것 같다. 시각도 아니고 청각도 아니고 하지만 제일 중요한 모달리티인 느낌이랄까. 언어는 co-training할 때 사용하고 마지막엔 결국 시각, 청각, 촉각만으로 학습이 이뤄지지 않을까 생각한다. 물리적으로 존재하는 로봇 등 뒤에 사람이 다가가서 텍스트로 입력넣을 일은 없을 것 같아서...
Physical AI에서 청각이 지금까지와는 다른 형태로 이해될 것이라 생각한다. 지금까지 AI에서 다루던 청각은 보통은 사람의 목소리나 음악 정도였지만 physical AI에서는 청각에서 얻을 수 있는 정보가 많다. 위험 감지로도 쓸 수 있고, 내가 한 행동의 결과를 청각을 통해 얻을 수도 있다. 유리병이 깨진다던가, 무언가를 친다던가, 등등. action과 결부된 청각. 이 데이터를 시뮬레이션 속에서 얻을 수 있을까? 소리까지 시뮬레이션 되는 환경은 모른다. 배틀그라운드는 소리 어떻게 시뮬레이션했을까?
즉 realtime vision, hearing, touch 를 처리할 수 있어야 한다. 이런 측면에서 discrete한 transformer를 언제까지 쓸까도 의문이다. 정보 이해에는 최고지만 실시간 처리에 부자연스럽다. 지금까지는 그래도 실시간을 최대한 discrete하게 쪼개서 넣는 방식이 최고인 것 같다.
출력
실시간 오디오와 액션. 피지컬에서는 결국 이거 2개다. 물론 representation learning을 언어 기반으로 모두 할 것이기에 할라치면 텍스트 아웃풋도 쉽게 가능하긴 할 것 같다. Physical AI를 온라인으로도 쓸 수 있어야 하긴 하니까. 실시간 오디오와 액션이 되면 그래도 텍스트 아웃풋은 쉽게 될 것 같으니 오디오와 액션에만 집중해보자.
Robix처럼 액션과 오디오를 모두 내뱉을 수 있어야 한다. 항상 오디오로만 답변해도 안되고, 액션으로만 해도 안되고, 둘다 해서도 안된다. 상황에 따라 그냥 묵묵히 행동으로 보여줘야 할 때도 있고, 마음에 안 들면 따질 때도 있고, 궁시렁대면서 행동해야 할 때도 있다. 실시간으로 적절한 모달리티로 출력해야 한다.
실시간성
기본적으로 지금까지의 AI들은 시간축에 대한 고려를 크게 하지 않았다. 텍스트, 이미지 부분은 아예 없었고 오디오 쪽 정도만 이런 고려가 많았다. 추론할 때 추론이 다 되는 것을 기다리지, 실시간으로 무언가를 해야 하는 느낌은 전혀 아니다. 하지만 이제 Physical AI가 메인스트림이 될 것이고 여기에서 실시간으로 외부의 입력에 따라 즉시 사고를 업데이트하고, 실시간으로 AI 행동에 대한 결과를 보며 계획을 수정하고, 실시간으로 움직이게 된다. 처음 이런 모먼트를 상상했던 것은 GPT-4o였다. (이 전에 있을 수도 있다.) GPT-4o는 전화를 하면서 사람이 중간에 끼어들면 멈추고 사람의 말을 듣고 그거까지 같이 생각해서 답변했다. 물론 이상적인 방식은 아니다. 개발자가 알고리즘으로 사람이 말하면 멈추고 듣고 그것까지 텍스트로 넣어서 다음 추론 시킨 것뿐이다. 하지만 궁극적으로는 항상 귀가 열려 있고 사람의 소리가 아닌 큰 경적 소리, AI를 속삭이며 부르는 소리, 시끄러운 매미 소리 등 다양한 형태의 소리에 대해 소리의 크기와 무관하게 소리의 중요도에 따라 반응해야 한다. 이는 개발자의 알고리즘으로 불가능하고 실시간으로 소리를 듣는 형태, 더 확장하면 실시간으로 시각, 청각, 촉각을 모두 느낄 수 있는 형태가 되어야 한다.
인터페이스
ChatGPT 이전까지 일회성이고 단방향이었던 모든 AI 인터페이스가 ChatGPT 이후에 대화가 기본 인터페이스가 되었다. 이제 실시간 상호작용 인터페이스가 기본이 되지 않을까? 지금의 대화는 아무래도 좀 더 시간과 무관하고 실시간성이 아예 없는 형태이기 때문이다. 그리고 물리적으로 존재하는 공간에서는 그 시간을 제대로 파악하고 있는 것이 중요하기도 하다.
제어 전략
"실시간성"과 이어지는 이야기다. GPT에게 정리를 부탁했다.
| 제어 전략 | 핵심 아이디어 | 장점 | 단점 | 대표 사용 사례 |
|---|---|---|---|---|
| Time-driven (duration-based) | 동작 시간을 미리 예측하고, 그 시간 동안 실행 후 다음 명령 발행 | 구현 단순, 빠른 반응 | 실제 동작이 duration과 불일치하면 오류 발생(빠름/느림/실패 구분 어려움) | 단순 반복 동작, 일정 주기 작업(예: 컨베이어 라인) |
| Receding-horizon (MPC류) | 일정 horizon H를 계획하고, 매번 일부(k step)만 실행 후 재계획 | 환경 변화에 유연, 안정적 피드백 | 잦은 재계산 → 연산 비용 높음 | 로봇 조작, 자율주행, 드론 제어 |
| Hold-last (command repetition) | 새 명령이 도착할 때까지 마지막 명령을 반복 실행 | 구현 간단, 통신 지연에 강함 | 명령 불변 시 오버슈트·충돌 위험 | 원격 조작, 네트워크 제어(텔레오퍼레이션) |
| Event-driven (completion-conditioned) | 목표 도달·접촉 등 완료 조건 충족 시까지 명령 유지 | 의미적 완료 보장, 접촉 작업에 강함 | 종료 조건 모호하면 블로킹 위험 | 그립핑, 삽입, 조립, pick-and-place |
| Preemption / Blending | 새 명령이 오면 이전 명령을 부드럽게 인터폴레이션 전환 | 동작 전환이 매끄럽고 진동 감소 | 전환 중 의도 불일치 가능(특히 접촉 작업) | HRI, 휴머노이드, 드론, 연속 동작 제어 |
보통 대부분의 VLA는 일정 시간마다 추론하고 이전 추론을 덮어쓴다. Receding-horizon control이라고 볼 수 있다. Kiro는 duration-based에 중요 액션은 event-driven하게 관측 결과를 기준으로 판단한다.
태호의 접근
이런 세상의 흐름에서 내가 생각하는 최적의 접근 방식은 한번에 휴머노이드를 만들기보다는 이런 큰 그림을 가지면서 즉시 돈을 벌 수 있는 (= 즉시 사용자들에게 가치를 만드는) 조그마한 버티컬 로봇들부터 하나씩 만들어보는 것이다.
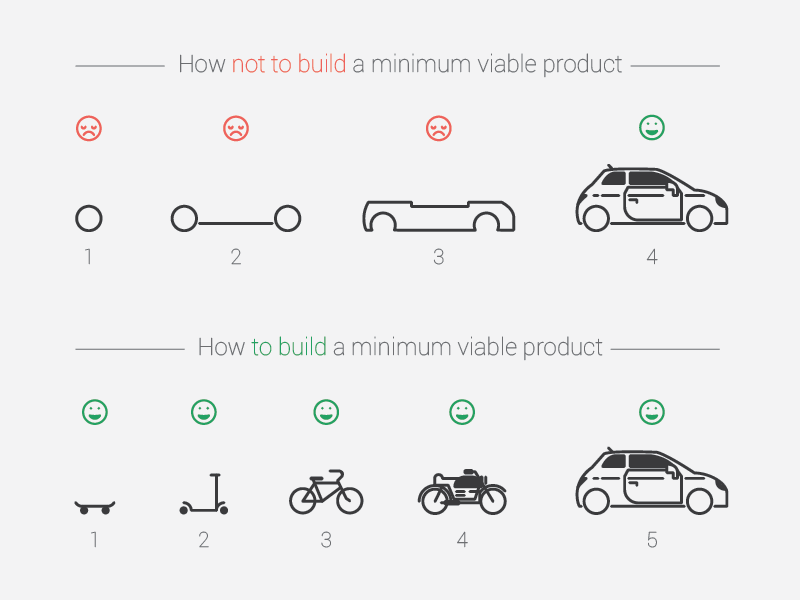
흔히 말하는 린스타트업의 접근 방식이다. 이것이 유일한 접근 방식이라고는 생각하지 않지만 나랑 제일 잘 맞았고 다른 사람에게도 추천하는 방식이기도 하다. 한번에 자동차를 만들려고 하게 되면 중간에 쉽게 지치게 된다. 마치 RL에서 나오는 문제 같다. search를 적당히 하다가 intermediate reward가 있어야 이 방향이구나 학습을 하는데 reward를 한번도 못 받으니 계속 search만 하다가 멘탈이 나갈 수 있는 상황이다. 옛날의 내가 항상 이랬다.
문라이트하면서 이 부분을 제일 의식적으로 신경썼고 이렇게 하니까 번아웃도 안 오고 꾸준히 높은 에너지 텐션을 유지하면서 2 -> 3 -> 4 .. 이렇게 발전시켜나갈 수 있었다.
Physical에서도 한번에 완벽한 걸 하기보다 작은 것부터 하나씩 해보는 것이다. 이를 위한 내 첫 스텝이 Kiro인 거고. Kiro를 하면서 느낀 점은 정말 문제 셋팅 잘했다. 휴모노이드와 비교하면 쉬운 문제(물론 그래도 많이 어렵다)이고 이걸 만드면서 로봇을 만들 때의 어려움들을 쉬운 버전으로 다 겪을 수 있다. Kiro 다음은 조금 더 어려운 문제 & 사람들에게 책스캔보다 더 큰 가치, 그 다음은 좀 더 큰, 이렇게 한 스텝씩 나아가다 보면 정말 큰 가치를 만들어낼 수 있지 않을까? 휴머노이드를 만들고 이것으로 어떻게 가치를 만들지 이 2가지가 분리되는 것보다 하나의 형태로 사람들에게 만들어내는 가치 자체에 집중해서 린하게 만들어내는 것이 나에게 훨씬 잘 맞고 좋았다.
다음 "오늘의 연구"
하나하나 읽다 보니 생각보다 시간이 꽤 소요됐다. 다음에는 논문 단위로 읽지 말고 토픽 단위로 해서 GPT와 빠르게 정리하는 형태로 해야겠다.
오늘의 연구 + AI의 미래 끝!



