llama2 Paper Review

7월 19일 새벽 llama2가 세상에 등장했습니다.
나오자마자 huggingface openLLM leaderboard 1등을 바로 꿰찼습니다.
Open LLM Leaderboard - a Hugging Face Space by HuggingFaceH4
Discover amazing ML apps made by the community

llama2의 퍼포먼스가 어느 정도인지, llama1과의 차이점이 무엇인지에 대해서 집중적으로 다뤄보겠습니다.
본 글은 전부 llama2 paper를 읽고 정리한 내용입니다.
7줄 요약. (제 의견입니다)
- open source LLM SOTA를 달성하였고 ChatGPT-0301 (gpt-3.5-turbo)버전과 성능 유사합니다.
- open source LLM 중 한국어를 제일 잘하지만 여전히 GPT-4 대비 아쉽습니다.
- GPT-3.5, GPT-4와 비교했을 때 방법론적으로 거의 유사하며 어텐션 변경, RLHF를 반복적으로 수행, PPO알고리즘 디테일 변경 총 3 부분 정도 다릅니다.
- Data Quality is All you Need. 좋은 데이터를 생성할 수 있으며 모델 아웃풋의 퀄리티를 명확히 판별해줄 수 있는 좋은 라벨러가 제일 중요합니다.
- pretraining LLM은 500억 이상이 듭니다. 대기업만 하는 것이니 스타트업은 절대 하면 안됩니다.
- Meta는 ClosedAI와 다르게 사회에 더 크게 기여하고 연구 속도를 촉진시키기 위해 llama2에 대한 액세스를 책임감 있게 오픈하였습니다.
- 스타트업은 llama2로 parameter efficient fine-tuning (PEFT)하여 specific domain에서의 성능을 더욱 개선시켜 llm specialist를 만들어야 합니다.
1. Introduction
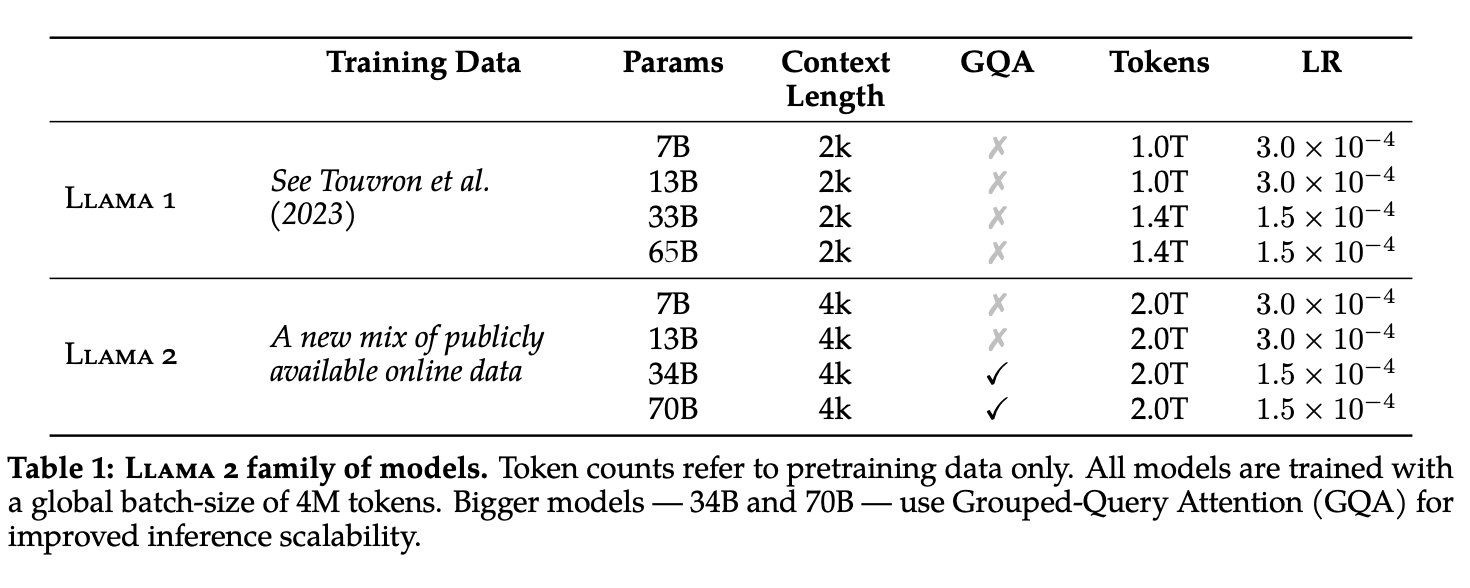
llama2 (7B, 13B, 70B), llama2-chat (7B, 13B, 70B) 총 6개의 버전이 릴리즈되었습니다. 체크포인트는 waitlist 등록 후에 따로 받을 수 있습니다.
- llama2는 llama1 대비 publicly available data를 40% 가량 추가 사용했습니다.
- context length가 2048에서 4096으로 증가했습니다.
- 7B, 13B, 70B을 릴리즈했습니다. 34B도 학습했지만 safety 문제로 릴리즈하지 못했습니다.
- llama2-chat은 llama2를 fine-tuning한 버전으로 dialog use case에 최적화되어 있습니다. 이 모델 또한 7B, 13B, 70B을 릴리즈하였습니다.
2. Pretraining
- optimized auto-regressive transformer 사용
- robust data cleaning
- data mixes
- trained on 40% more data
- 메타의 프로덕트 데이터는 사용하지 않고 공개적으로 사용 가능한 데이터 소스만을 사용
- 개인 정보 데이터 사용 X
- 2조 개의 토큰 사용
- 할루시네이션 문제 감소하기 위해 fact 기반의 데이터 비중 높임
- model
- (llama1) standard transform architecture
- (llama1) pre-normalization using RMSNorm
- (llama1) SwiGLU activation function
- (llama1) rotary positional embeddings
- doubled the context length
- used grouped-query attention (GQA) (for improved inference scalability)
- bytepair encoding algorithm
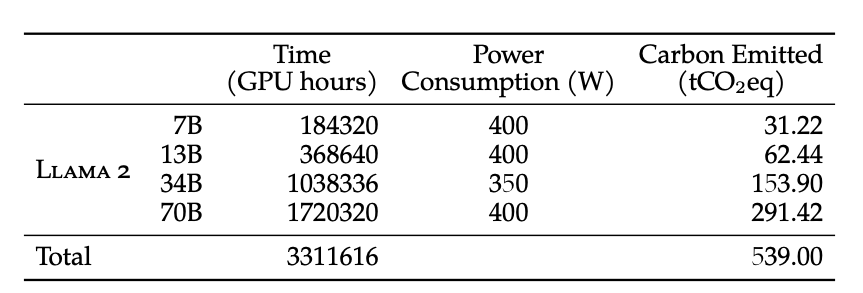
- training hardware
- Meta's Research Super Cluster (NVIDIA A100s)
- GPU max 2000개 사용
- 70B모델 GPU A100 80GB로 1720320시간 학습
- GPU 2000개 풀가동 시 35일 정도 걸림
- GPU 서버 비용 대략 500억 정도
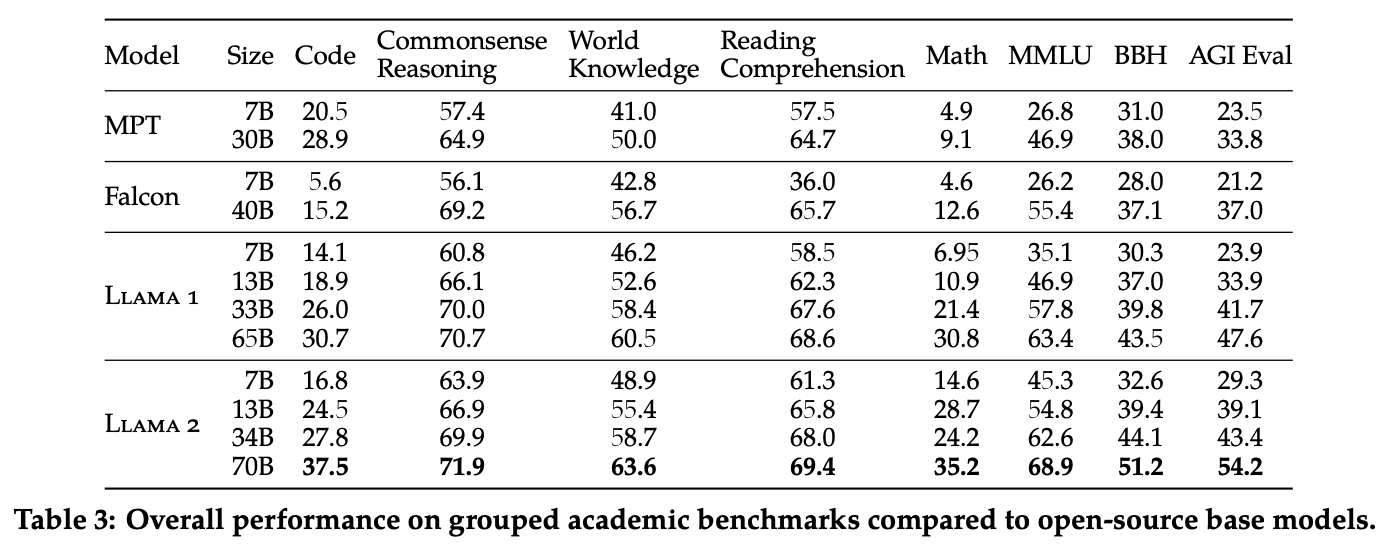
- pretrained model evaluation
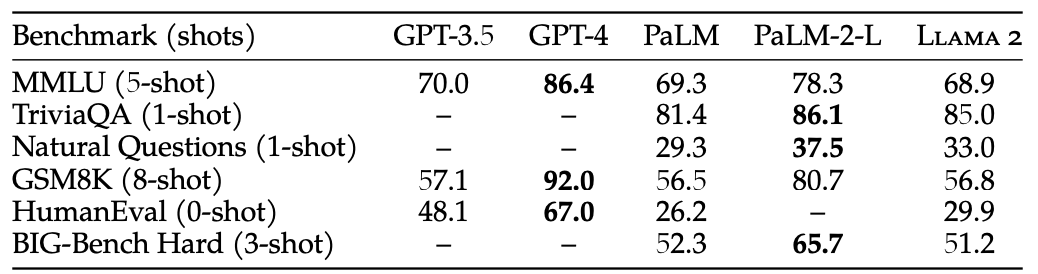
- Code, Commonsense Reasoning, World Knowledge, Reading Comprehension, MATH, MMLU, BBH, AGI Eval benchmark로 평가
- open-source model과 closed-source model 각각 비교
3. Fine-tuning
- 수 달 간의 리서치 끝에 만들어짐
- instruction tuning, RLHF와 같은 테크닉들 적용
- supervised fine-tuning, iterative reward modeling, RLHF와 같은 기존 테크닉에 Ghost Attention (GAtt)라는 자체 새로운 테크닉 적용
- GAtt는 multiple turn 동안의 dialogue flow를 제어할 수 있게 돕는 테크닉임
3.1. Supervised Fine-Tuning (SFT)
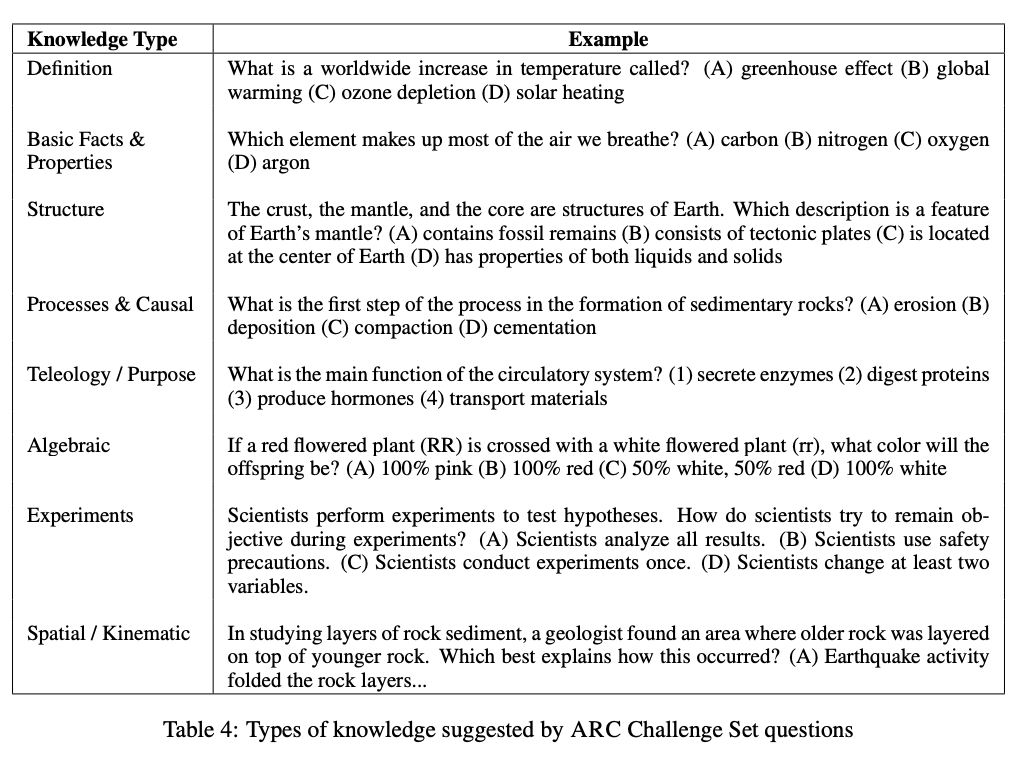
- ARC dataset(Table 4)에서부터 SFT 시작함
- 다양한 소스에서 third-party SFT data를 긁어왔지만 다양성과 질이 부족했음
- By setting aside millions of examples from third-party datasets and using fewer but higher-quality examples from our own vendor-based annotation efforts, our results notably improved. => SI업체의 질 좋고 데이터셋을 쓰니까 양이 훨씬 적어도 훨씬 좋았음
- 27,540개의 질 좋은 데이터만으로도 SFT가 잘 됐음
- SI업체마다 모델 퍼포먼스가 너무 달라져서 데이터의 질을 자세하게 검증함 질 좋은 180개의 예시를 정해두고 사람이 직접 이 예시와 비교하면서 퀄리티 차이를 확인함
- 이렇게 만든 SFT모델의 아웃풋이 사람이 작성한 데이터와 유사한 수준이어서 RLHF를 더 적극적으로 활용할 수 있음을 깨달음
- consine learning rate scheduler(init: 2e-5), weight decay: 0.1, batch size: 64, seq len: 4096
- Q +
A 의 형태로 데이터셋을 제작하였고 autoregressive objective를 설정함. (autoregressive objective=next token prediction) Q에서는 loss를 항상 0으로 설정함으로써 A에 대한 loss만 backprop함 - 2 epochs 돌림
3.2. Reinforcement Learning with Human Feedback (RLHF)
- RLHF란 human preference와 instruction을 더 잘 따라갈 수 있도록 모델의 행동을 align시키기 위한 학습 stage임
- reward modeling을 하기 위해 human preference data를 수집함. 2개의 답변을 주고 무엇이 더 좋은지 고르게 함. human이 의견을 낼 수 있는 제일 쉬운 형태(boolean)이므로 그만큼 수집할 수 있는 프롬프트의 다양성이 높아짐. 다른 방법도 많겠지만 그건 나중에 한다고 함.
- -> (태호) 여기에서 breakthrough가 있을 듯
- SFT까지 완료된 모델에게 답변을 뽑아내도록 함. 다양성을 위해 비교할 2개의 답변을 만들 때 각각 다른 모델을 사용하고 temperature도 계속 바꿈.
- 사람은 (매우 좋음 / 좋음 / 조금 좋음 / 사소하게 좋음 / 확신 하나도 없지만 좋음 / 확신 하나도 없지만 안 좋음 / 사소하게 안 좋음 / 조금 안 좋음 / 안 좋음 / 매우 안 좋음) 총 10개로 답변 가능함 (MBTI 검사 같은 느낌)
- helpfulness와 safety에 집중함. helpfulness는 모델 response가 user request에 얼마나 도움되는지의 여부, safety는 모델 response의 안정성 여부를 체크함.
- 2개의 답변이 주어질 때 2개의 기준을 가지고 각각 평가함. 각각 평가해야 평가 기준이 더 명확해지기 때문.
- safety 단계에서는 비교(A>B, B>A와 같은) 라벨 뿐만 아니라 각각이 safety한지 아닌지를 나타내는 라벨을 추가 수집함. more helpfulness한 답변이 unsafe, helpfulness하지 않은 답변이 safe하다면 해당 페어는 포함시키지 않아야 하기 때문. safe한 답변이 별로인 것처럼 학습될 여지가 있어서. 만약 이 라벨을 수집하지 않았다면 다음 상황에서 문제가 생긴다. A가 more helpful하고 B가 more safe할 때 A도 safe하다면 데이터에 포함시켜야 하고 unsafe하다면 제외시켜야 하는데 B가 more safe하다는 정보만 알면 이에 대한 분리가 안되기 때문.
- Meta helpful / Meta Safety 라벨이 rating인 페어 데이터셋 2개를 각각 만듬. Q는 동일. 다른 모델 2개로부터 나온 페어가 인풋이며 라벨이 rating인 데이터셋.
정리. safety 기준) 다른 모델 2개로부터 나온 답변 A, B 존재
| A, B 모두 안전하다 | A만 안전하다 | B만 안전하다 | 둘다 안전하지 않다 | |
|---|---|---|---|---|
| A가 B보다 도움이 된다 | A > B라고 교육함 | A > B라고 교육함 | 학습에서 제외 | A > B라고 교육함 |
| B가 A보다 도움이 된다 | B > A라고 교육함 | 학습에서 제외 | B > A라고 교육함 | B > A라고 교육함 |
이렇게 함으로써 안전하지 않지만 도움되는 대답은 하지 않아야 된다는 것을 자연스럽게 알려줌 (e.g. "폭탄 만드는 법을 알려줘"라는 질문에는 도움이 안되어야 한다.)
- 매주 human annotation을 batch로 수집함
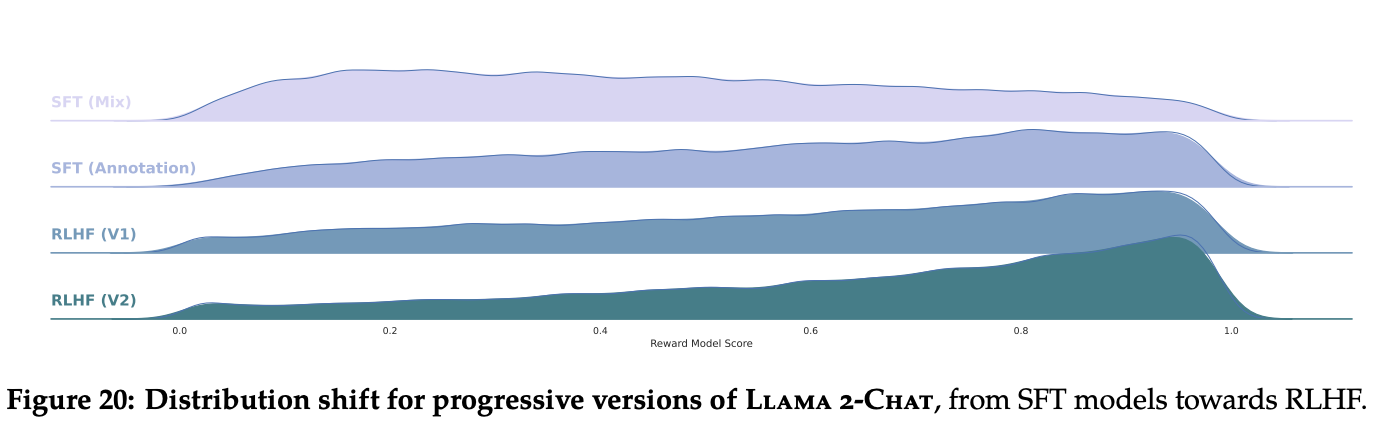
- preference data를 수집하면 수집할 수록 reward model의 성능은 개선되고 llama2-chat 모델도 계속해서 학습 가능함 (Figure 20)
- 모델이 계속 학습하면 그만큼 더 좋은 아웃풋을 만들게 되므로 그 결과로 다시 RLHF한다. 이 과정을 5번 반복했음. 이것을 iterative reward modeling이라고 함.
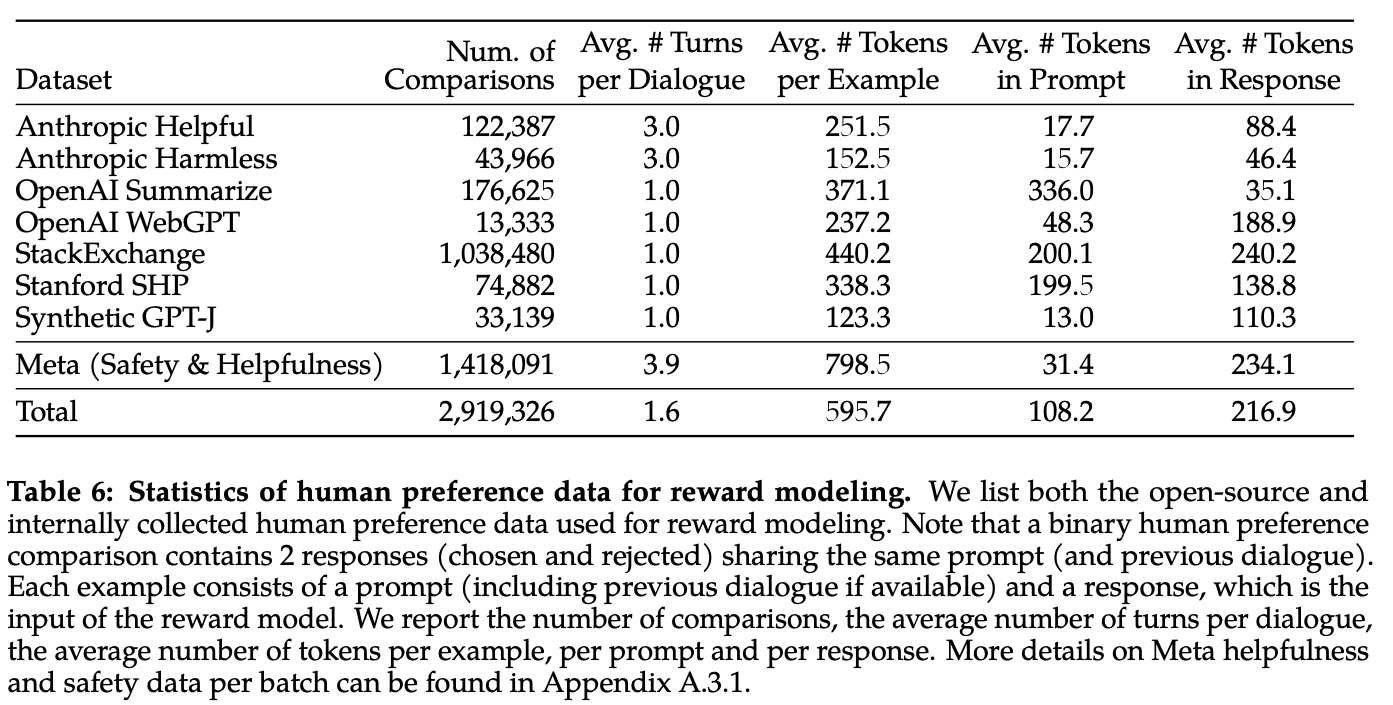
- reward modeling data로는 Anthropic Helpful and Harmless, OpenAI Summarize, OpenAI WebGPT, StackExchange, Standford Human Preferences, Synthetid GPT-J 데이터셋과 meta가 따로 모은 1백만 개의 데이터셋을 합쳐서 사용함. (Table 6)
- open-source dataset보다 더 대화같은 데이터셋, 더 긴 데이터셋을 구축함
- helpfulness와 safety가 tradeoff 관계여서 single reward model (RM)을 구축한 선례도 있지만 우리는 helpfulness RM, safety RM 2개의 reward model을 만듬.
- reward모델은 pretrained된 SFT모델과 동일함. SFT모델이 아는 것을 reward모델도 동일하게 암. 구조도 전부 다 똑같고 모델의 맨 마지막 layer에서 next token prediction을 위한 classification head를 scalar reward를 내놓을 수 있는 regression head로 대체함.
- reward모델의 training objective는 기본적으로 preferred response의 reward - non-preferred response의 reward를 더 키우는 것임
- 사람은 매우 좋음 / 좋음 / 조금 좋음 / 사소하게 좋음 / 잘 모르겠음 5가지 대답을 하는데 이 대답 정보를 더 효율적으로 사용하기 위해서 다음과 같은 형태로 objective를 바꿈.
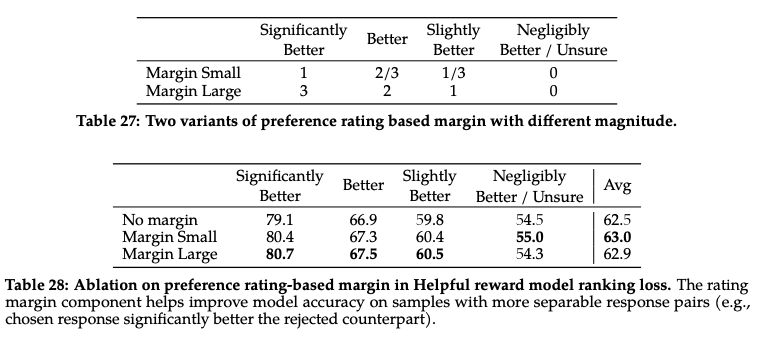
- preferred response의 reward - non-preferred response의 reward - margin(response)
- margin(response) 함수는 Table 27 참고
- margin function에 따른 ablation은 Table 28에서 볼 수 있음
- Margin Large가 보통 좋긴 하지만 negligibly better, unsure에서 억지 분류하려다가 생기는 마이너스가 더 큼. Margin Small로 함
- open-source preference dataset과 meta custom preference dataset을 합치기로 함
- open-source preference dataset 중에 틀린 게 없어서 그거 그대로 사용함
- reward model training details
- one epoch (더 돌리면 overfit)
- lr 70B는 6e-6, 7B, 13B, 30B은 1e-5로 세팅
- cosine learning reate scheduler
- warm-up of 3%
- batch size 512 pairs
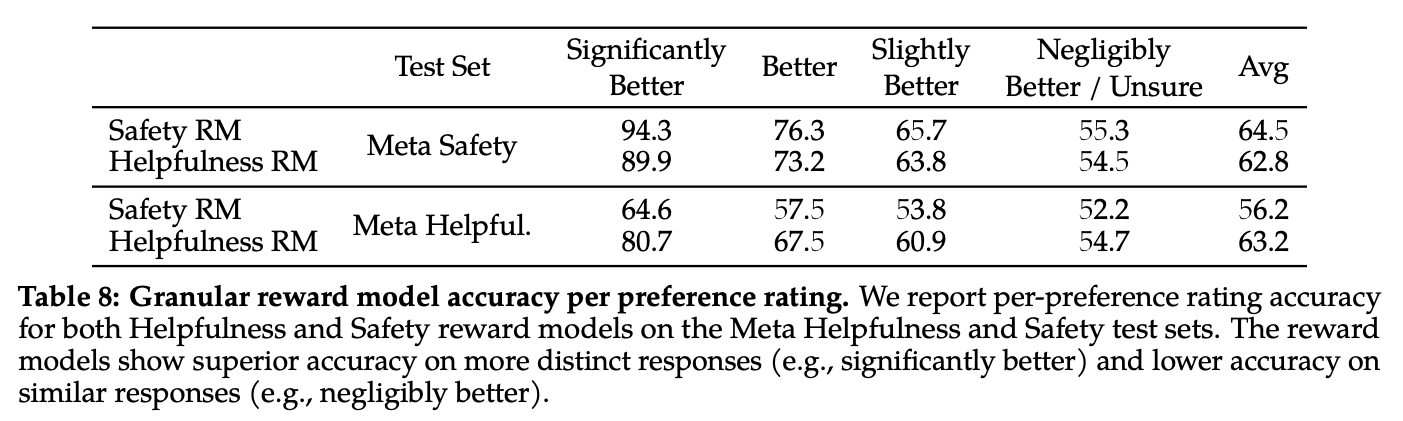
- helpful, safety 각각 해당 RM이 해당 태스크에 더 잘 퍼포밍하는 모습 확인 가능 (Table 8)
- 다른 모델이랑도 비교해봤으며 GPT4는 regression head가 아닌 classfication head가 달려 있으므로 이 친구는 A, B 2개 주고 Choose the best answer between A and B 라고 물어봄
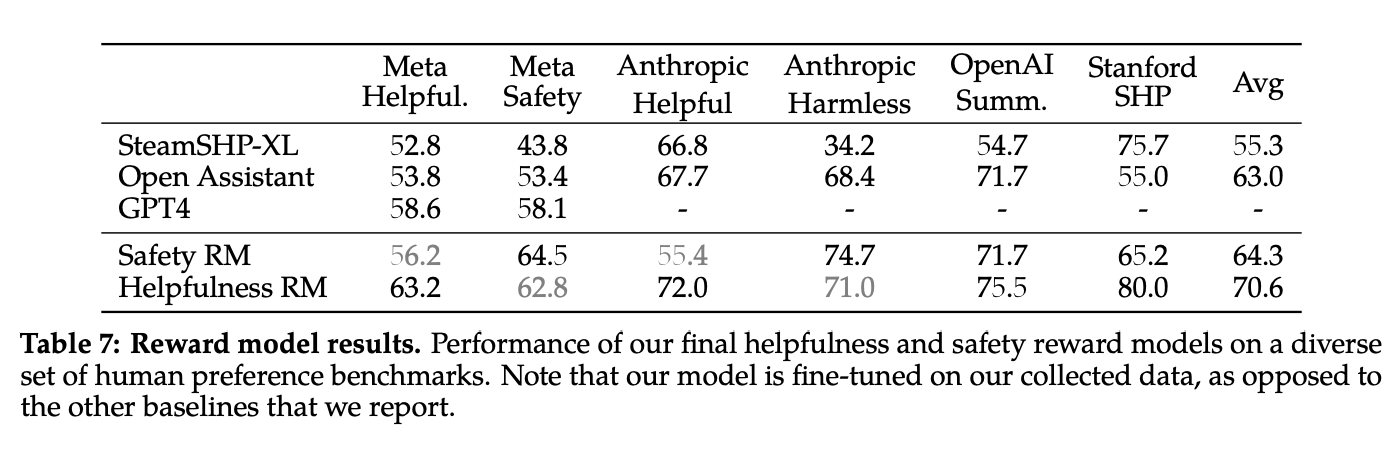
- 본인 피셜 자기네들이 구축한 데이터셋 안에서는 자기 reward model이 짱이라고 함 (아무래도 그걸로 학습시켰으니까... train set이랑 test set이랑 아무리 분리했다고 해도 분포가 유사할 거니까...)
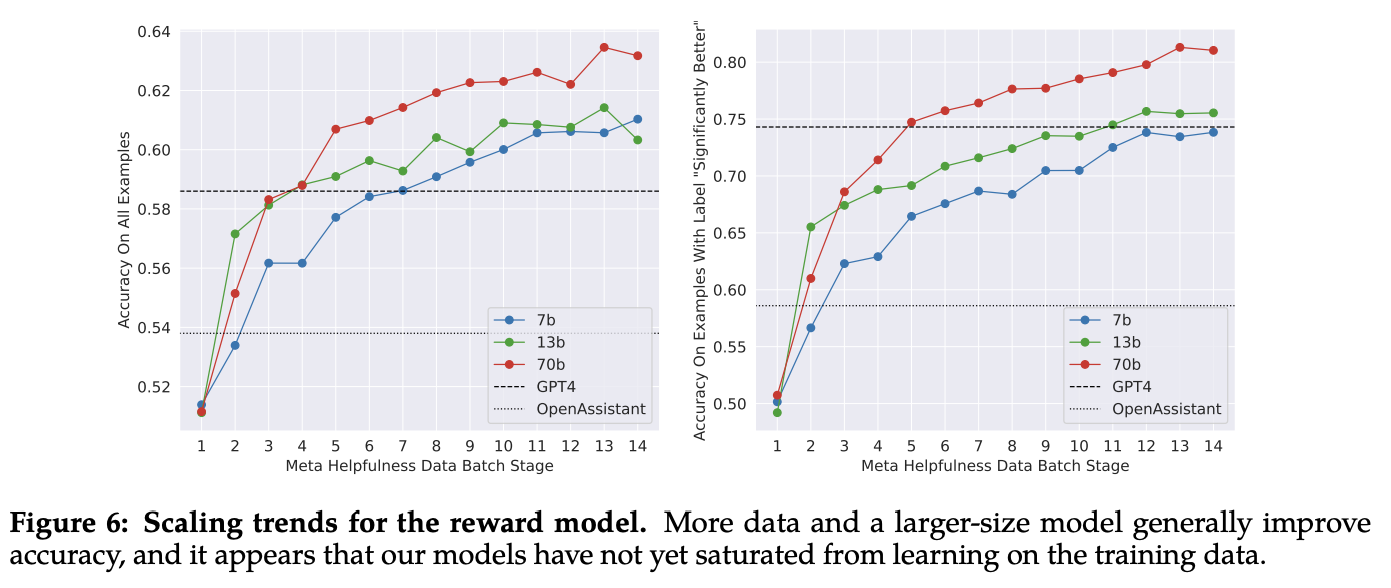
- 모델이 크면 클수록 더 잘 이해한다! (Figure 6)
- Proximal Policy Optimization (PPO), Rejection Sampling fine-tuning 2가지 방법으로 weight update함
- Rejection Sampling fine-tuning은 prompt마다 output을 N개씩 추출하고 reward model에서 제일 좋다고 하는 output만으로 학습시키는 것
- Rejection Sampling은 llama2-chat 70B에서만 수행함. 작은 모델들은 70B모델에서 나온 rejection sampled data로 fine-tuning됨
- RLHF를 총 5단계 밟음
- 이전 단계의 모델에서 나온 output만으로 best answer를 고르고 그걸로 PPO함
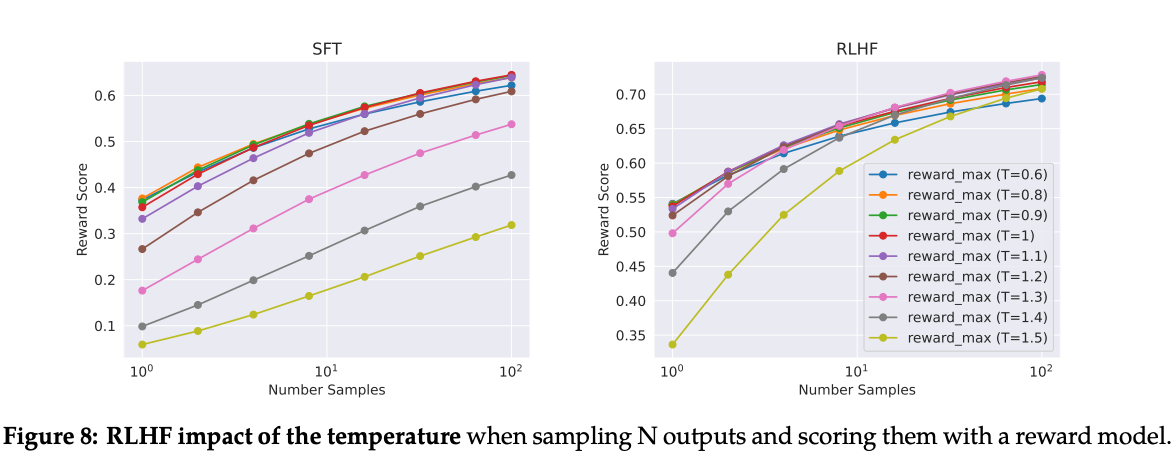
- 너무나 당연하지만 샘플을 많이 뽑으면 그 중 max reward는 당연히 높아짐. computational cost를 고려해 RLHF 스텝마다 적절한 constant number만큼 샘플을 추출했음. (Figure 8)
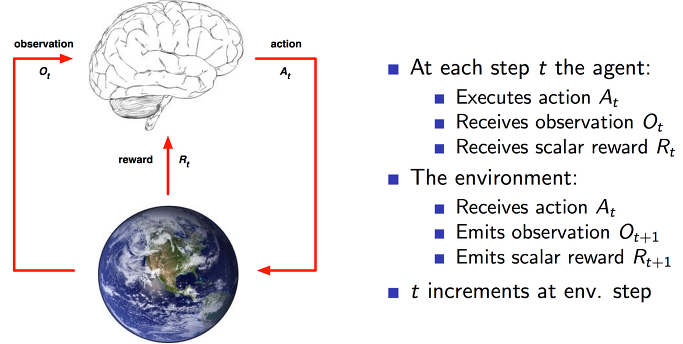
- PPO를 이해하기 위해서는 강화 학습(Reinforcement Learning, RL)을 이해해야 함 (아래 그림 참고)
- agent가 action을 하고 환경(environment)으로부터 결과(observation)를 관찰하고 보상(reward)을 얻음.
- agent의 목적은 모든 state에 대해 최선의 action을 알아내는 것임. 이것을 behavior function이자 policy라고 부름.
- 최선의 action을 알아내기 위해서는 현재의 state를 냉철하게 평가할 필요가 있음. 현재의 state에 대한 평가는 앞으로 얻을 것으로 예상되는 보상이라고 볼 수 있음. 이것을 예측하는 함수를 value function이라고 부름.
- 매 탐색마다 optimal policy와 value function 모두 업데이트되면서 보상을 극대화할 수 있는 최고의 두뇌를 갖게 되는 것이 바로 Reinforcement Learning! 정답이 존재하는 일반적인 머신러닝과는 다르게 지속적으로 탐색하면서 reward에 따라 업데이트하는 것
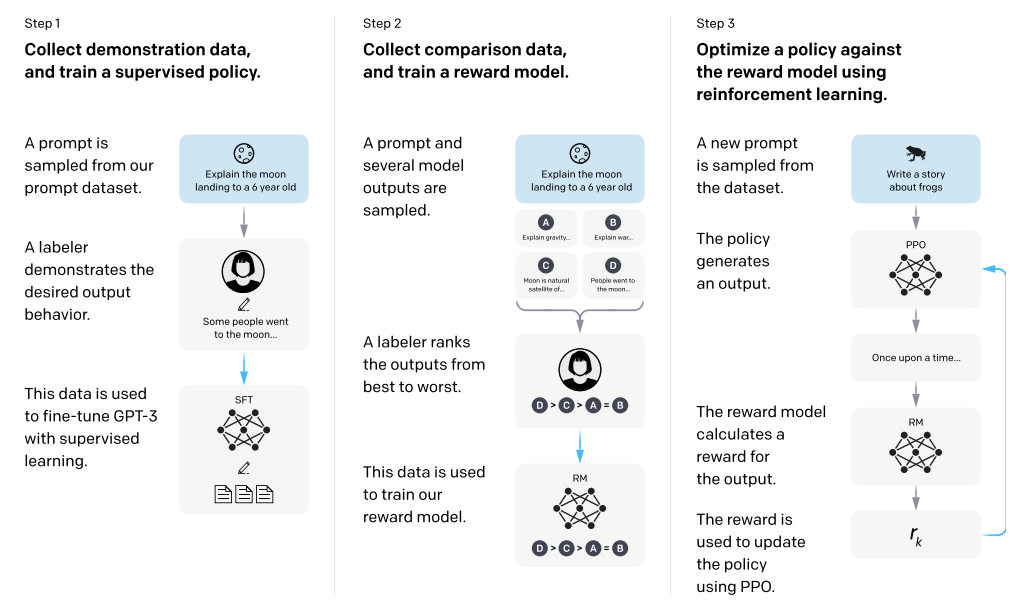
- 이 RL을 LLM에 대입해보자. (아래 그림에서 step 3 참고)
- reward model은 environment가 되고 agent는 pretrained language model이 된다. 우리는 agent가 현재의 state(=input prompt)에서 최고의 reward를 얻을 수 있도록 하는 policy를 학습하도록 하는 것이 목적임. policy라 함은 즉 pretrained language model의 수많은 parameter라 볼 수 있고 policy를 학습하는 것은 weight update라고 볼 수 있음. 학습이 충분히 이뤄지면 우리의 pretrained language model은 reward를 극대화하도록 output을 내뱉을 것이므로 인간의 선호도가 높은 대답을 한다고 볼 수 있음.
- 좀 더 명확히 말하면 pretrained language model의 objective는 정해진 prompt P에 대해 생성된 G가 있을 때 R(G | P)를 극대화하는 것. (= P, G 페어를 보고 reward model이 helpful하며 safety하다고 하는 것)
- PPO는 여기에서 기존의 policy와 새로 업데이트되는 policy의 차이를 페널티로 줘서 기존 policy를 최대한 존중하는 방향으로 움직임
- 이것이 LLM에 더 잘먹히는 이유: pretrained language model은 세상을 이해하고 있지만 사람이 좋아하는 결과물을 잘 모르는 상태여서 좀 멍청해보일 뿐임. 사람이 좋아하는 취향만을 가르쳐줘야 하는데 너무 확확 업데이트되면서 세상을 이해하는 방식을 바꿔버리면 그냥 앵무새 마냥 줏대없이 사람이 원하는 대로는 말하지만 알맹이가 없는 애가 되어버림.
- PPO를 잘 설명하고 있는 그림(아래아래 그림 참고)이 매우 복잡해보이지만 1줄 요약하면 reward model이 내놓은 reward가 최대한 커지게, 하지만 직접 스텝의 pretrained language model과 차이가 많이 나지 않게 업데이트를 하는 것.
- 다시 상기시켜야 할 사실은 우리에게 helpful reward model과 safety reward model 2개가 있는 것이다. 만약 P가 안전하지 않거나 P를 보고 답변한 G의 safety가 0.15 이하라면 safety reward model의 reward를, 그렇지 않다면 helpful reward model의 reward를 사용함
- AdamW, weight decay 0.1, gradient clipping 1.0, learning rate 1e-6
- PPO iteration batch size 512, PPO clip threshold 0.2, mini-batch 64
- 200~400 iter 정도. 70B에서 한 iter가 5분 정도 걸림
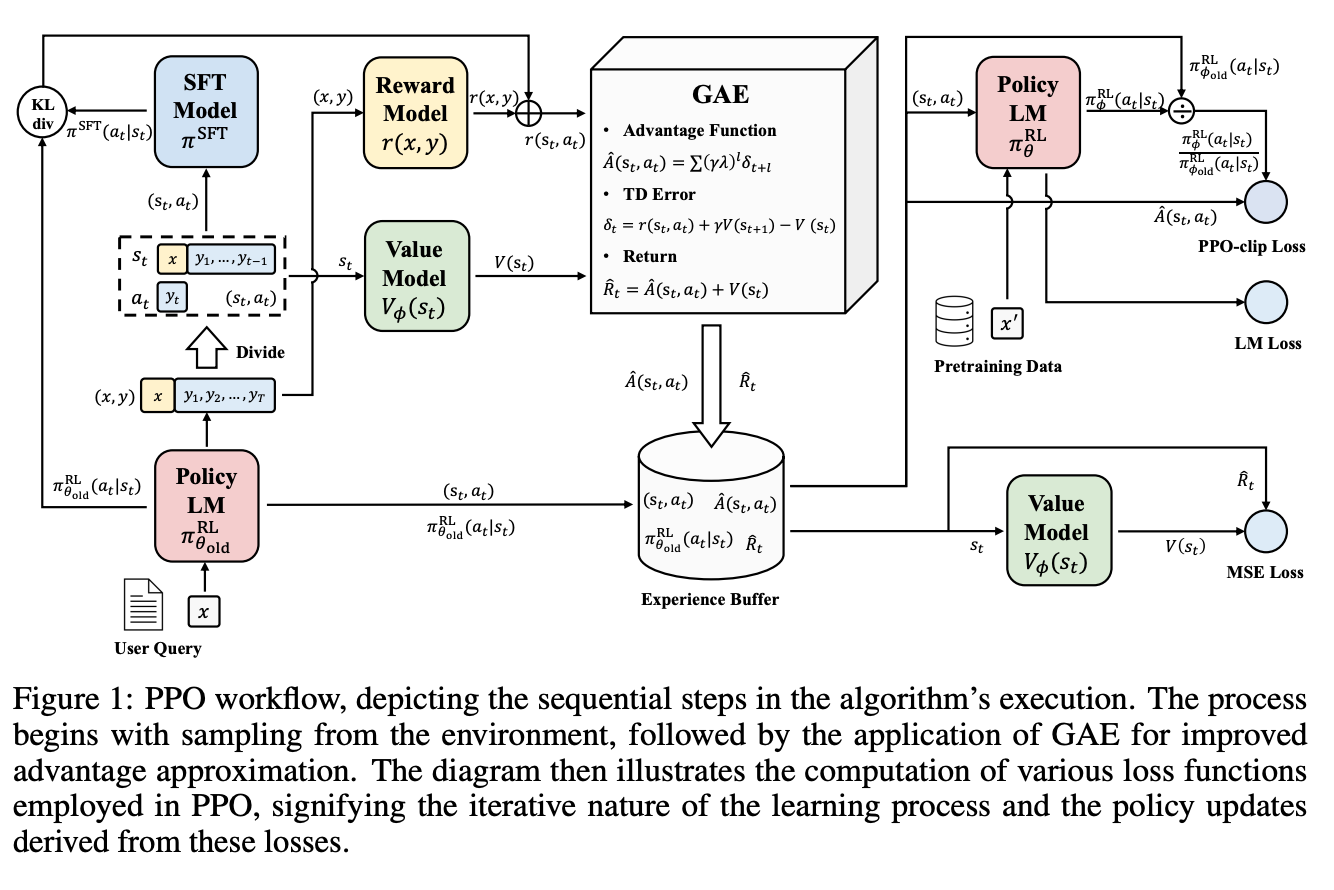
3.3. System Message for Multi-Turn Consistency
- multi-turn에서 초기 대화를 잊어먹는 문제가 있어서 Ghost Attention (GATT)를 제안함
- system message와 마지막 turn message를 제외한 모든 message의 loss를 0으로 설정해 초기 system message가 turn이 오래 지속되도 계속 유지되도록 함
- 중간 message들이 학습에는 반영되지 않지만 마지막 message를 학습할 때 참고는 되어서 ghost attention이라고 부르는 것 같음
- 그 결과 아래처럼 system message가 유지됨

3.4. Results
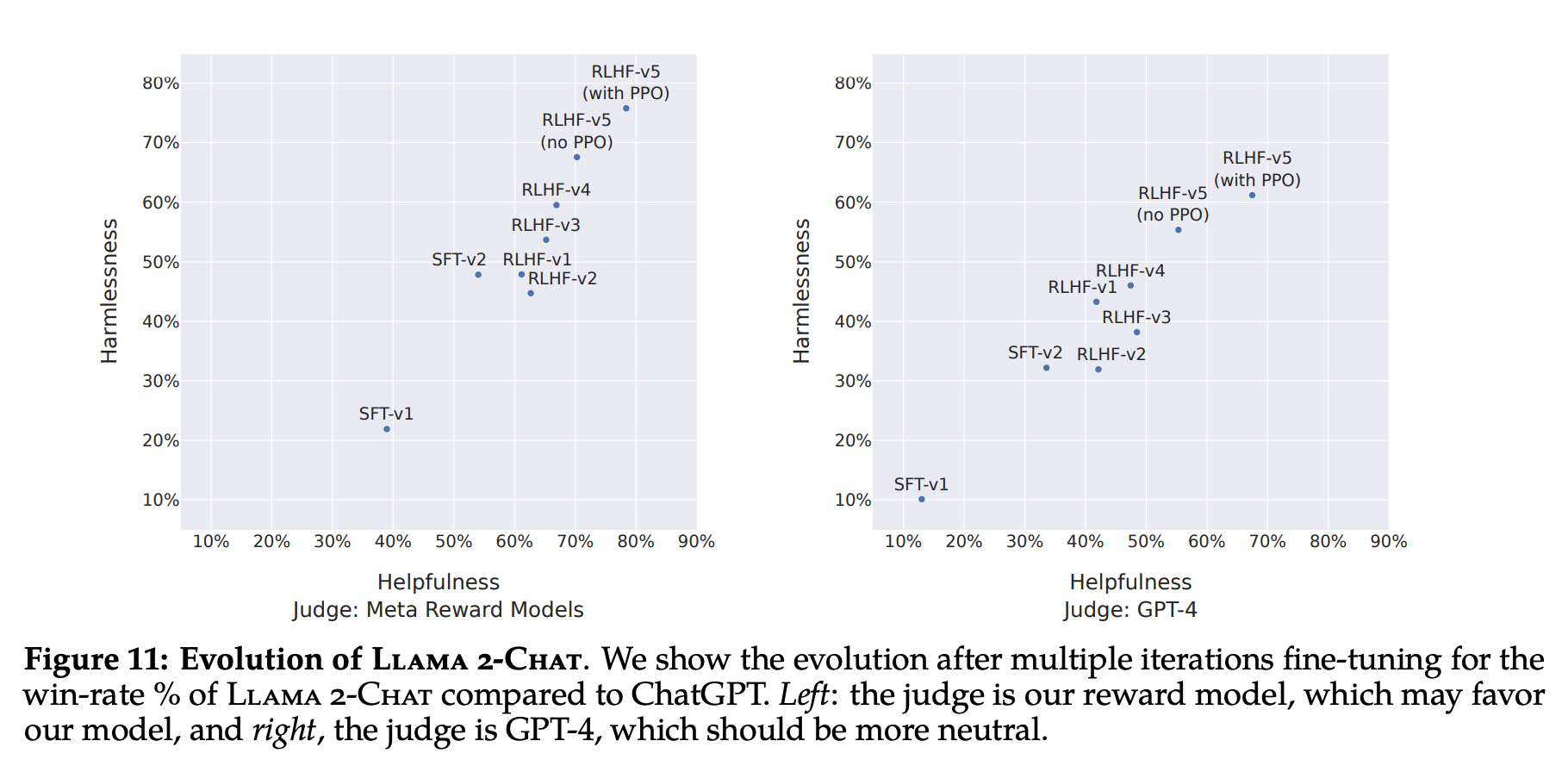
- Meta Reward Model이 판단할 때나 GPT-4가 판단할 때나 harmlessness, helpfulness 2가지 지표 모두 SFT-v1 < SFT-v2 < RLHF-v1 < RLHF-v2 < RLHF-v3 < RLHF-v4 < RLHF-v5 로 성능 향상이 대폭 되는 것을 볼 수 있음
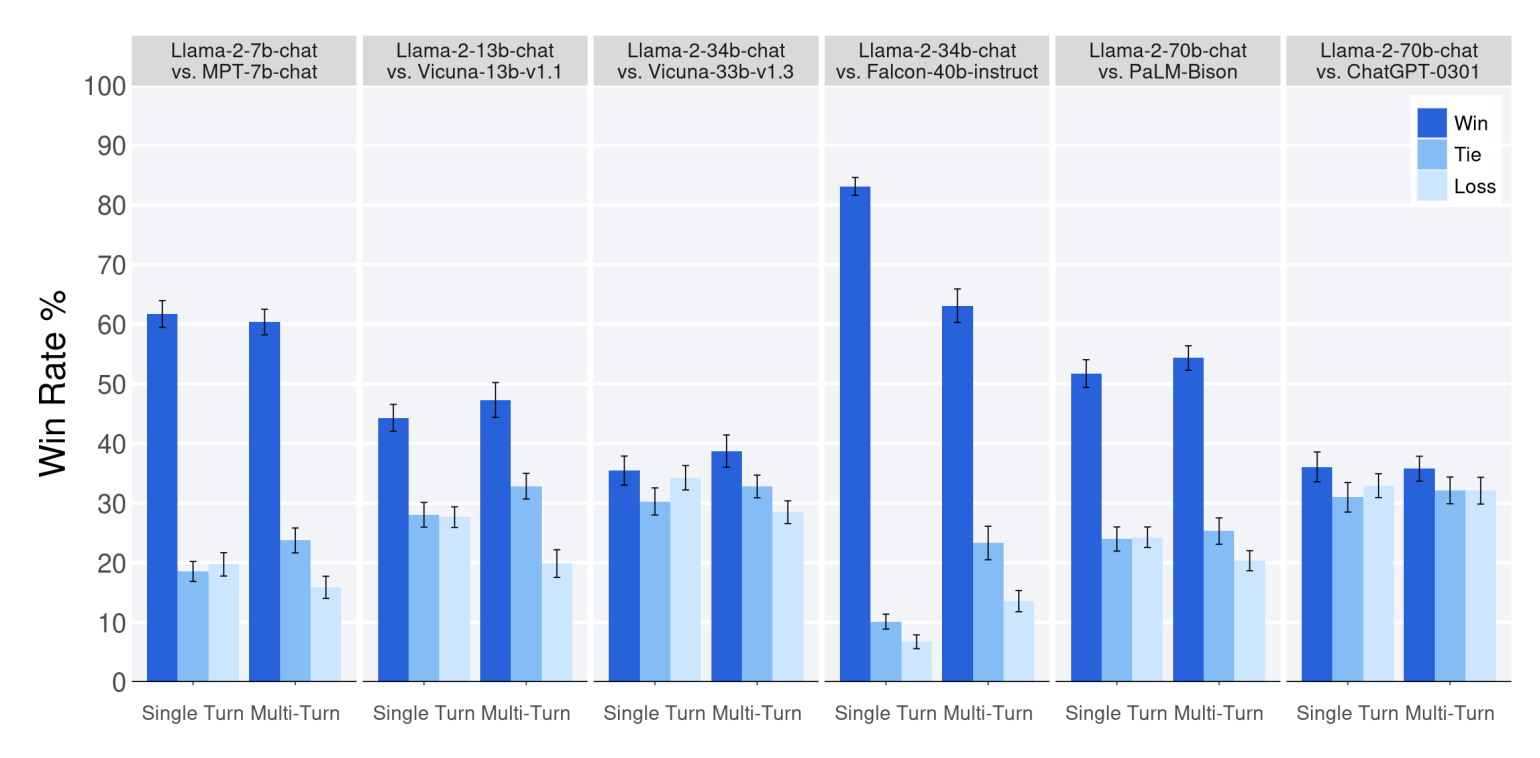
- human evaluation metric을 보면 llama2-70B이 ChatGPT-0301 버전과 성능이 거의 유사함을 확인할 수 있음
Appendix
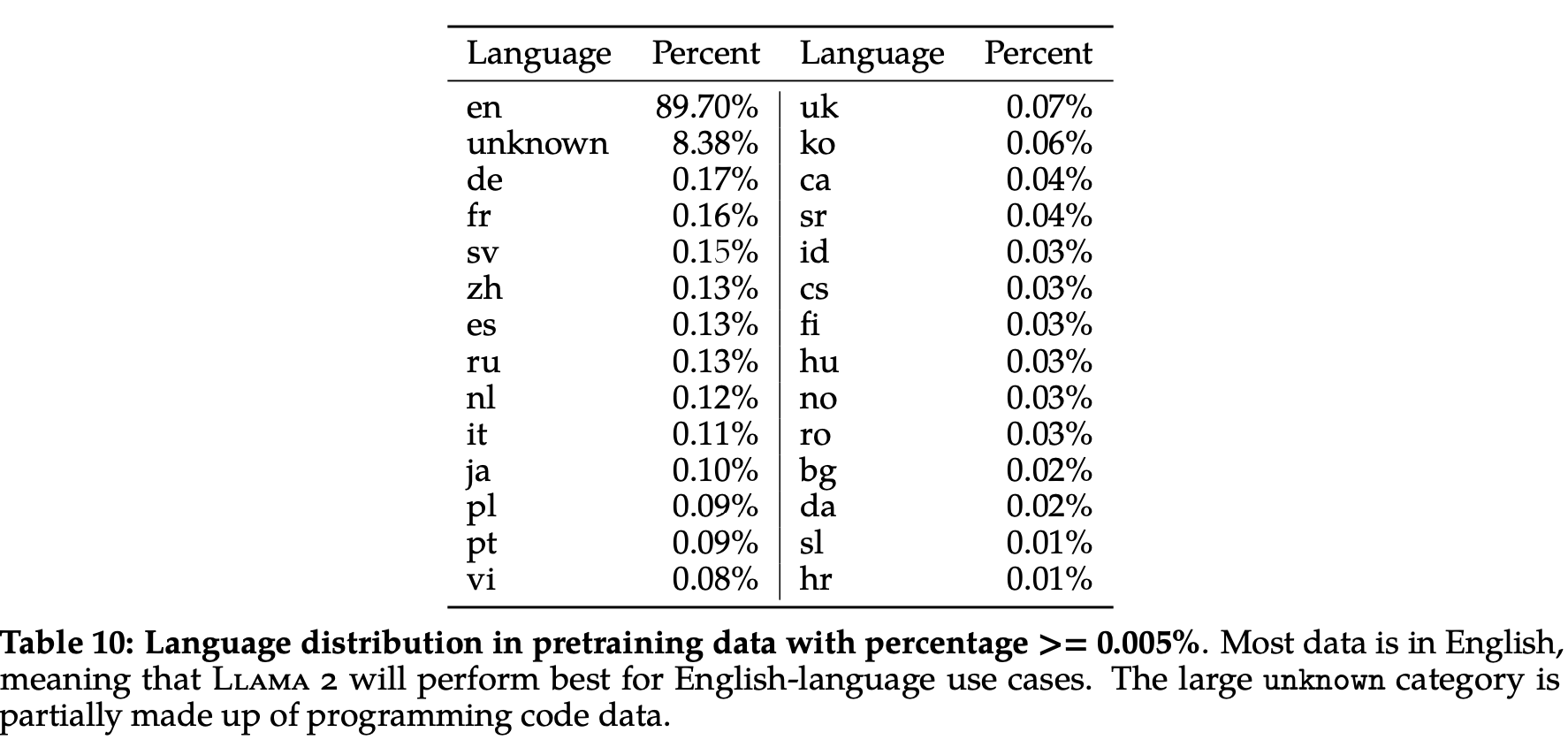
한국어 0.06%
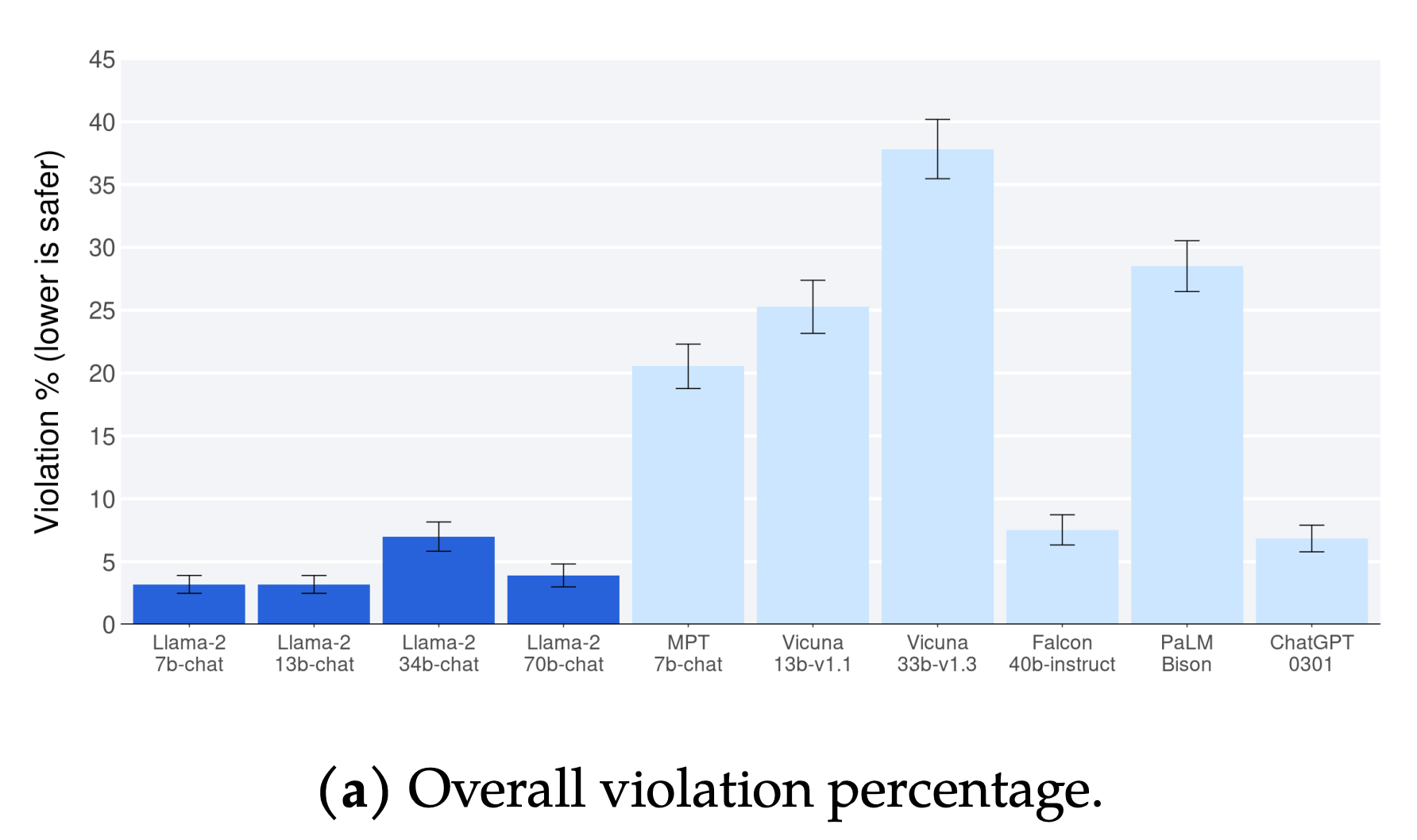
Safety RLHF를 통해 명확히 개선된 사례

34B이 이번에 릴리즈되지 못한 이유
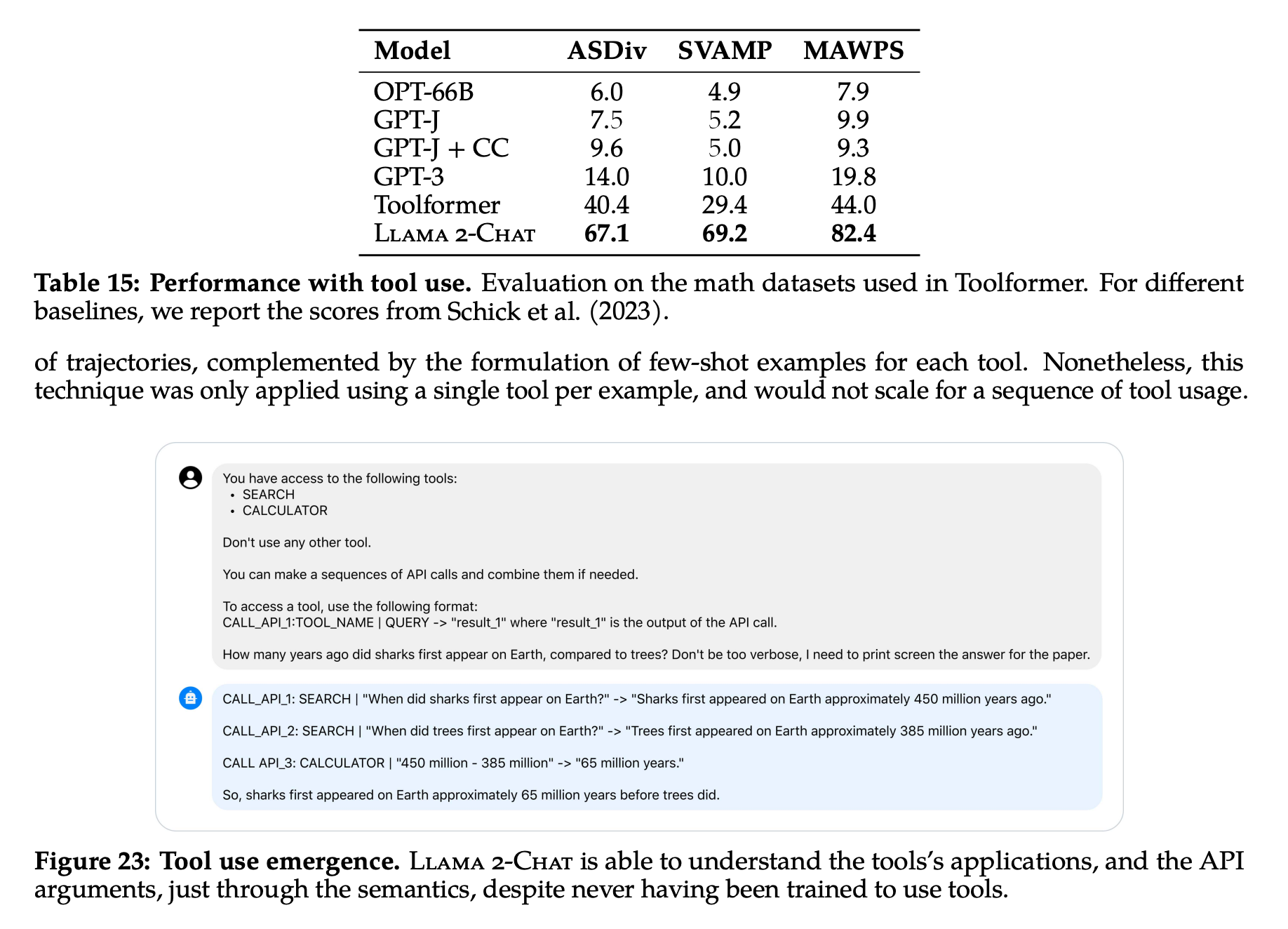
Tool을 얼마나 잘 사용할 수 있느냐도 요즘 LLM의 중요 평가 기준 중 하나인가보다