Domain specific architectures for AI inference
요약
- 무어의 법칙 둔화로 인해 프로세싱 자체의 성능 개선이 어려운 상황에서 Domain Specific Architecture만이 유일한 선택지가 됨. (DSA: 특정 상황에, 특정 도메인에 특화된 칩 설계)
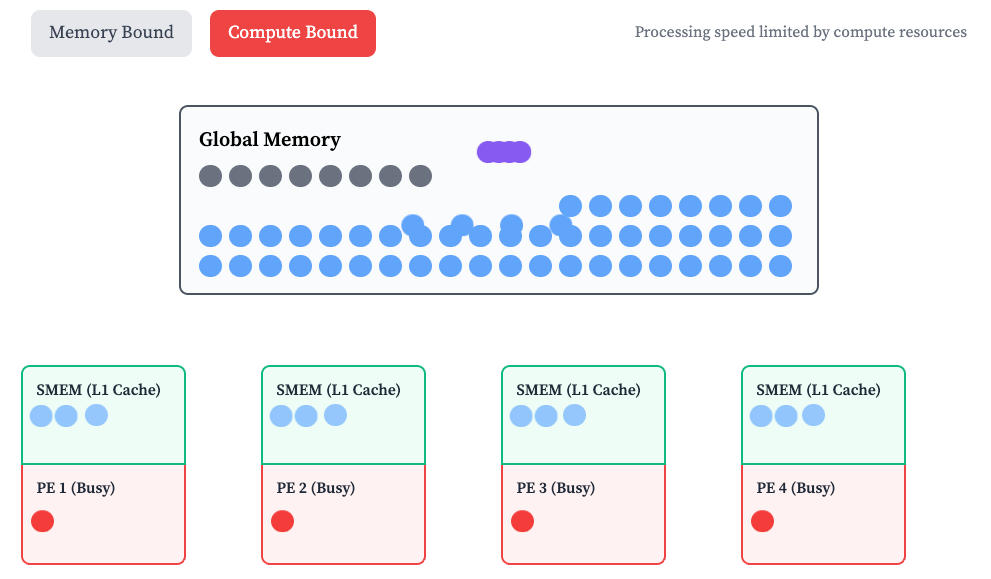
- 메모리 사용(데이터 이동)을 최소화하여 Compute Bound (메모리가 아닌 컴퓨팅 리소스에 의해 처리 속도 제한이 걸리는 상황)을 만들어야 함.
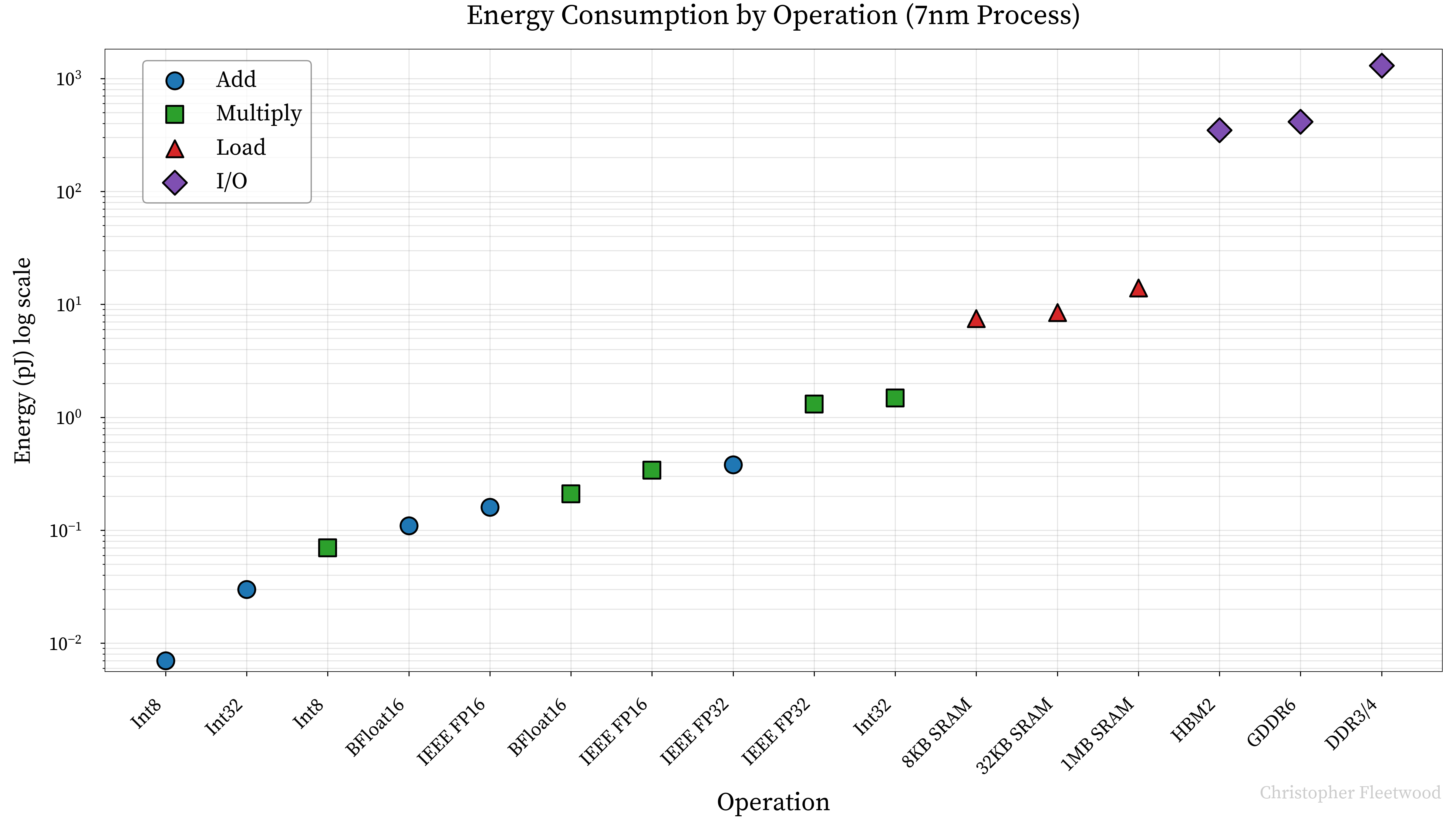
- Lower precision: Hardware support for low precision data types.
- 정밀도와 성능의 트레이드오프. (정밀도가 높아지면 만티사 비트 갯수의 제곱에 비례해서 full adder 가 필요하고 연산량이 많아진다)
- First class asynchronicity: Design for asynchoronous transfers from day 1.
- 로봇하면서 절실히 느끼는 부분이다. 일반적인 SaaS에서는 거의 다 동기 API를 활용하는 경우가 많았는데 앞으로 비동기성이 대세가 되지 않을까? 뉴럴넷에서도 사실 추론할 때 모든 부분이 다 동기라고 봐야 한다. 사람의 시냅스는 실시간으로 모두가 함께 비동기적으로 추론하는데 뉴럴넷은 처음부터 끝까지 순서대로 쭉 추론하고 서로의 결과를 기다린다. 하드웨어에서도 비슷한 느낌이라고 이해했다. 글로벌 메모리에서 Shared 메모리로 비동기로 계속 옮기는!
- Dedicated hardware for memory transfers: Dedicated hardware for tensor aware memory transfers.
- CPU를 거치지 않고 메모리에서 메모리로 바로 이동시킬 수 있도록 하자.
- Optimal memory hierarchy for AI: Replace your cache hierarchy with an outsized scratchpad.
- CPU Cache에서 제일 큰 가정을 하는 건 temporal locality, spatial locality인데 GPU에서는 이 가정이 모두 깨진다. 한번 텐서를 활용해 추론하면 끝나기 전까지 다시 쓸 일이 없다. GPU 전용 최적화를 하면 비동기적으로 텐서를 shared memory로 계속 옮기고 공간이 충분히 있어야 하며 우리가 포기할 수 있는 것은 메모리 지속 시간이다. 한번만 사용되면 되므로 오래 들고 있어야 할 필요가 없다.
- Matrix Multiplications & Attention: For a single accelerator, turn the memory bandwidth up to 11.
arithmetic intensity: the ratio of operations performed to bytes accessedops:byte: the ratio of the accelerators "math" bandwidth and memory bandwidtharithmetic intensity>ops:byte면 compute bound!- 프로세서가 항상 일하게 계속 일감 메모리가 던져줘야 함!!
- memory bound가 아닌 compute bound가 되는 순간을 FFN에서 계산해보면 batch size 295 이상일 때
- SHA, MHA 모두 캐시 사이즈 너무 커서 DeepSeek에서 Multi Latent Attention(MLA)도입
- Scaling out: Design for scale-out from day 1 & Dedicated communication hardware should complement compute hardware.
- 요즘 모델은 너무 커서 단일 가속기에서 동작하지 않아 샤딩해야 하고 이로 인해 가속기 간의 통신 텀도 최적화 문제에 추가됨
ops:comms: the ratio between the number of operations we can perform to number of bytes we can send between accelerators- communication bound에서 compute bound로 넘어가는 조건을 비슷하게 계산할 수 있음
- 통신 관리를 위한 전용하드웨어 반드시 있어야 함. 모델이 커짐에 따라 comm bound 쉽게 걸림
- Implications of test time compute scaling
- 지금까지는 다 트레이닝 위주의 최적화였다면 앞으로는 test-time 컴퓨팅이 더 많아지면서 이 최적화가 더욱 중요해질 것. 2가지 차원 존재: 직렬 추론 & 병렬 추론
내 생각
이 블로그 읽고 하드웨어에 대한 개념과 철학을 어느 정도 정립했다. 결국 다양하게 주어진 자원 속에서 우리가 반드시 만족해야 할 조건, 우리가 최적화해야 할 목표를 세운 뒤 달성하는 최적화 문제이다.
이런 최적화 문제가 일반적인 엔지니어링에서 만나는 문제들이다. 데이터 엔지니어링에서도 그렇고, 알고리즘 속도 개선에서도 그렇고, 심지어 제품 만들 때도 그렇다. 이런 문제를 풀 때는 항상 내가 해결해야 하는 범위가 무엇인지 포기할 수 있는 것이 무엇인지를 생각하고 그것들을 과감하게 포기하고 내가 원하는 것을 얻을 수 있는지를 고민해야 한다. 그렇게 domain specific하게 풀다보면 어느 순간 모든 것이 추상화되면서 모든 것이 해결되는 순간이 오기도 하는 것 같다.
Accelerator에서는 memory bound, comm bound, compute bound 세 친구가 서로 민폐가 되지 않으려고 열심히 싸운다. 그래도 compute bound가 제일 핵심이니 이 친구는 민폐여도 뭐 그럴 수도 있지라는 마인드인데 memory, comm은 절대 자기가 병목이 되어선 안되니 열심히 하는 느낌이다. 키로에서는 hardware bound, control bound, cost bound 등이 있고 control bound를 해결하고 나니 다시 hardware bound에 직면한 상태이다.
이 이상으로 내가 하드웨어, 컴퓨터 칩에 대해 더 깊게 이해하기 위한 다음 스텝은 직접 설계하고 만들어보는 것이라고 생각한다. 지금 당장은 내가 이걸 함으로써 세상에 만들어낼 수 있는 가치가 없어 지금 하진 않을 테지만 앞으로 내가 하는 수많은 도전들 속에서 언젠가 chip bound가 생겨서 이 칩을 설계하는 날이 온다면 지금까지 쌓아뒀던 개념과 철학들을 사용해서 chip bound를 해결하는 날이 오길 바란다. (Kiro에서 할 수도 있고!)