사람과 함께 사는 AI

평화로운 주말 오후 커피 한잔 마시면서 블로그 읽고 위 내용과 내 생각을 정리한 글.
AI의 후반전
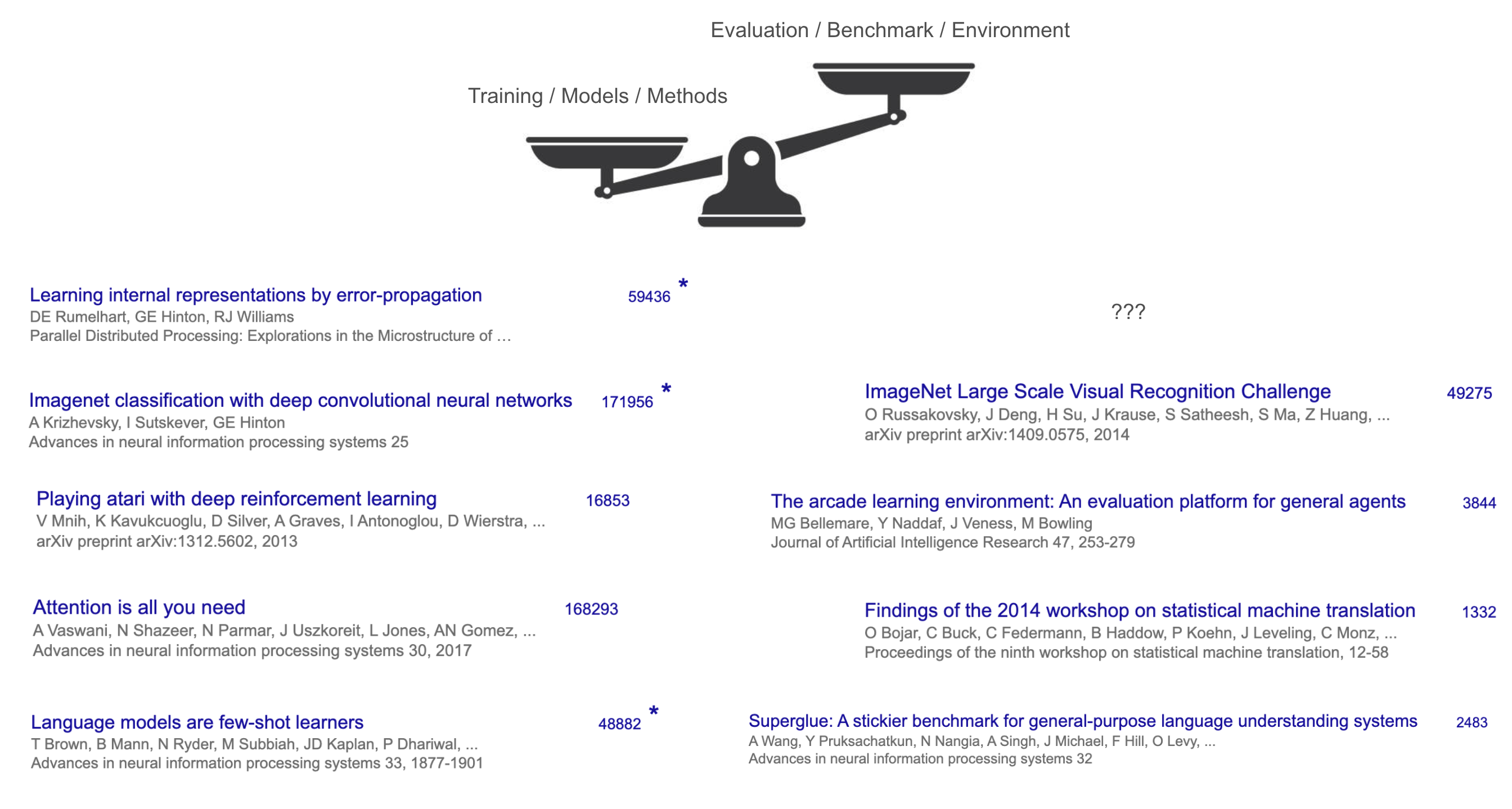
1. AI의 전반전(First Half) vs 후반전(Second Half)
- 전반전(First Half): 문제 해결을 위해 새로운 훈련 기법과 모델에만 초점 → AlexNet, Transformer, GPT-3처럼 “훈련 기법/모델”이 승부처였고, 벤치마크(ImageNet, WMT’14)는 수단에 불과했음.
- 후반전(Second Half): 초점이 평가와 문제 정의로 이동 → 이제는 모델보다 “어떤 문제를 정의하고, 어떤 평가로 진짜 효용을 검증할 것인가”가 더 중요해짐.
2. 강화학습의 재발견
- 수십 년간 RL은 “알고리즘”에 집착했음 (PPO, TRPO, DQN…).
- 하지만 실제로 중요한 건 알고리즘보다 priors(사전 지식)와 environment(환경)였음.
- 대규모 언어 사전학습 (RL priors)과 reasoning을 action space로 추가 (RL environment)하면서 RL이 비로소 일반화 가능해짐.
You can’t connect the dots looking forward; you can only connect them looking backward. - Steve Jobs
3. 레시피(Recipe)의 등장
- 현재의 레시피
- 대규모 언어 사전학습
- 스케일(데이터+연산+모델 크기)
- Reasoning
- 이 조합이 사실상 산업화된 ‘승리 공식’이 됨. 이제 대부분의 벤치마크는 이 레시피로 해결 가능.
4. Utility Problem
- AI는 이미 체스, 바둑, SAT, Bar, IMO, IOI 다 깨버렸는데 세계 경제·생산성은 생각만큼 안 변함.
- 이유: 현행 평가체계와 실제 효용 간의 괴리.
- 현재 평가: 자동화된 평가가 가능해야 하며, 테스트셋은 모두 독립적이어야 함
→ 연구자에겐 편리하지만 현실과 다름. - 현실: 인간 상호작용 필요, 연속적
- 현재 평가: 자동화된 평가가 가능해야 하며, 테스트셋은 모두 독립적이어야 함
- 이전에는 지능이 워낙 낮았기에 이런 강한 가정이 있어도 지능을 학습시킬 정도로는 충분했음. 현재는 general recipe를 통해 지능이 많이 향상되어 이 가정을 깨부술 때가 되었음.
- 따라서 “진짜 세상에서 유용한 평가 방식”이 필요.
5. 후반전의 게임 규칙
- 전반전: 새로운 방법 → 벤치마크 개선 → 논문 출판.
- 후반전: 새로운 평가/문제 정의 → 레시피로 해결하거나 새로운 요소 추가 → 진짜 인류에 유용한 가치 창출
- 즉, 앞으로는 연구자의 스킬셋이 알고리즘 발명보다는 문제 정의에 가까워져야 함.
사람과 함께 사는 AI
이 글을 읽으며 + 예전부터 하던 여러 생각들을 합친 나의 생각.
1. Environment
결국 제일 이상적인, 궁극적인environment는 이 우리가 살고 있는 우주 그 자체다. 이 복잡한 세상을 시뮬레이션할 수 없기에 우리는 여러 가정들을 통해 아주 극단적인 상황을 만들고 그 안에서 잘하는 AI를 만들어낸다. 아주 다양한 분야들로 매우 구체화시키고 각각 솔루션을 만들어낸다. 어느 정도 시간이 지나면 이 모든 것들을 통합하는 하나의 솔루션이 탄생한다.
- 전화기, 카메라, MP3, 내비게이션 등을 하나로 합친 스마트폰
- 우편, 방송, 사전, 상점 등을 하나로 합친 인터넷
- 편지, 전보 등을 하나로 합친 전화기
이렇게 하나로 합쳐지지 않았다면 세상은 매우 복잡하고 발전하기가 어려웠을텐데 다양한 목적을 하나로 통합하고, 혹은 하나의 목적을 위한 다양한 방법을 새로운 세대의 방법으로 통합하면서 문명이 발전해나간다.
AI에서도 CNN, Transformer 등이 나오며 이전의 수많은 모델, 학습 기법들을 하나로 통합하여 지금의 발전까지로 이르렀다. 점점 environment를 더욱 이 우주에 맞게 확장시켜야 하는 시점이다.
2. Evaluation
공간, 시간 모두 그렇다. parallel하게, i.i.d하게 평가하는 것이 아닌 실제 사람처럼 sequential하게, context-aware하게 평가해야 한다. 이런 평가를 하기 위해선 별도의 test set이라는 것이 존재할 수가 없다. 어떤 set을 만들든 optimize 대상은 이 set 이상으로 절대 넘어설 수 없다. 결국 내가 어떤 것을 잘해야 하고 어떤 것을 공부해야 하는지 스스로 찾아내고 판단할 수 있어야 한다.
인류의 test set은 수능, 고시, CPA 등등이 있다. 하지만 이런 test set에서 커트를 넘긴다고 지능이 높은 것도 아니고 커트를 못 넘는다고 지능이 낮은 것도 아니다. 이 test set에 과몰입하여 의미부여하게 되면 내 세상이 그 test set이 되어버린다. 사실은 이 세상의 distribution을 아주 극단적으로 좁디 좁게 표현한 test set일 뿐인데 말이다.
다만 인간은 스스로 존재 이유를 찾고 스스로 길을 개척하지만 AI는 다르다. AI의 제 1 목적은 인간의 목표 달성이다. 결국 AI는 얼마나 달성을 해주었는지를 기준으로 평가할 수 있다.
지금까지는 세션의 시간을 매우 짧게 하고 세션의 갯수를 매우 늘려 10,000개 중 몇 개를 달성했는지를 기준으로 발전해왔다. 하지만 인간 1명은 하나의 객체이며 병렬적으로 동작하지 않는다. 세계 경제, 생산성을 드라마틱하게 발전시키기 위해서는 제대로 된 하나의 큰 문제를 풀어야 한다.
이러한 평가 방식은 마치 수습 직원 채용과도 비슷하다. 채용할 때 우리는 절대 30분짜리 시험만으로 평가하지 않는다. 함께 일하는 환경(test time)과 평가하는 환경(training time)이 너무 다르기 때문이다. 이 환경을 맞추고자 1일 함께 일하기로 면접을 보는 곳도 있다.
즉, 앞으로 인류가 AI를 더욱 발전시키기 위해 나아가야 하는 방향은 AI와 함께 살며 가치를 만들어내어야 한다. 이 과정 속에서 정량적인 보상은 있으면 물론 좋겠지만 수학처럼 답이 명확한 문제는 이 세상에 매우 적기에 어렵다. 사람들이 사회를 구성해 함께 살아가는 것처럼 서로의 상호작용 그 자체가 AI를 발전시킬 수 있어야 한다.
즉 AI의 environment를 우리가 살고 있는 우주 그 자체로 맞출 때 진정으로 사람에게, 문명에게 도움이 되며 생산성을 향상시킬 수 있는 AGI에 다다를 수 있다고 생각한다.
이렇게 환경을 확장하기 전에 우리에게 반드시 필요한 것은 실시간으로 학습 가능한 알고리즘이다. 지금처럼 train / inference time이 명확하게 분리되는 상황이라면 위 environment에 나갈 수가 없다. train, inference가 동시에 되며 피드백 혹은 보상은 인간들에게 다양한 센서(시각, 청각, 촉각 등)를 통해 받는다.
이러한 알고리즘이 개발되면 우선적으로 웹 세상에서라도 AI가 독자적으로 살아가며 스스로 계속 발전할 수 있어야 한다. 그 이후의 단계는 Physical AI일 것이다. 세상을 웹으로만 보는 것과 실제로 행동하며 느끼는 것은 완전히 다르다. Physical AI를 통해 사람들과의 상호작용이 보다 풍성해지고 촉각이라는 새로운 센서도 추가된다.
우리가 함께 그려가야 하는 미래
- 실시간 학습이 되며,
- 물리적인 몸을 갖고 있고,
- 사람들과의 상호작용으로부터 배우는
AI를 만들 때 이 AI의 environment가 인류의 우주가 되며 정말 진정한 의미의 인공"지능"이 될 것이다.



